
- Рост числа сейсмических станций
- Много импульсного шума
- Вероятностный анализ сейсмической опасности
- — показана на рис. 2. Видно, что регрессия описывает измеренные значения пиковых ускорений грунта. Все точки относятся к одному землетрясению. Точнее говоря, сама регрессия построена по большому набору эмпирических данных разных землетрясений, но для простоты изложения приведены графики для землетрясения с магнитудой M=5.8. Скажем, вблизи Невельска (рис. 1) произошла серия землетрясений по магнитуде близких к M~6, вызвавшая разрушения в городе. На рис. 2 виден разброс значений пикового ускорения, который определяет стандартную ошибку σ=0.783 из . Натуральный логарифм пикового ускорения грунта для точек m=5.8 и r=10 км равен g(m,r)=4.868 (PGA=125 см/сек^2). Сейсмические воздействия с пиковым ускорением 0.7g (687 см/сек^2) соответствую ln a=6.532. Тогда вероятность того, что сейсмические воздействия A, вызванные землетрясением с магнитудой m=5.8 на расстоянии r=10 км, не превысят 0.7g (IX баллов) равна (см. Приложение): Здания не строятся на бесконечное время эксплуатации. У всего есть свой срок службы, и он определяется временем T. Рисунок 3. Схематическая иллюстрация сейсмических источников. В каком же случае воздействия от землетрясения с магнитудой M_i, очаг которого располагается в точке k (рис. 3), не превысят в заданном пункте величину ускорения a в течение последующего промежутка времени T? Первый ответ на такой длинный вопрос очевиден: если вообще не произойдет ни одного землетрясения за рассматриваемый временной интервал. Второй случай, менее очевиден: если произойдет одно землетрясение, но по определенному в закону затухания оно не вызовет ожидаемых сейсмических воздействий. Вообще за время T может произойти хоть два землетрясения или три или вообще Ns. Перефразируем сказанное в терминах вероятности. Примем упрощенную модель, в которой некоторая точка генерирует землетрясения только одной магнитуды. Посмотрим на табл. 1. В ней показаны различные исходы, при которых сейсмические воздействия не будут превышены: ни одного сейсмического события (0), одно , два (1 + 1), три (1 + 1 + 1) и т.д. Вероятность возникновения одного события в течение времени T равна p1, двух – p2, трех – p3 и т.д., ни одного – соответственно p0. Естественно, рассматриваемое множество исходов является полным, т.е. других вариантов нет: Вероятность того, что колебания от землетрясения заданной магнитуды не превысят заданное сейсмической воздействие в заданном пункте, обозначим как Pr, которая полностью задается через . Тогда вероятность того, что колебания от двух землетрясений не превысят заданное сейсмической воздействие, равна Pr*Pr, трех – Pr*Pr*Pr и т.д. При отсутствии землетрясений, очевидно, что вероятность непревышения равна 1. Таким образом, полная вероятность P того, что в течение времени T сейсмические воздействия в заданном пункте не будут превышены: Таблица 1. Вероятностные модели источника землетрясений заданной магнитуды в заданной точке. Тогда вероятность непревышения заданного уровня сейсмических воздействий a от сейсмического события с магнитудой M_i в точке k (рис. 3) в последующий промежуток времени T будет задаваться по аналогии с : где R_k – расстояние от очага землетрясения в точке k до пункта, в котором мы ожидаем сейсмические воздействия. Дальше – проще. Необходимо рассмотреть независимые реализации магнитуд M_i. Конечно, в большой сейсмологии есть исключения. Например, когда сильное землетрясение вызывает серию афтершоков (или другими словами повторные события с магнитудой чуть меньше, чем у главного события). Но для этого производят так называемую декластеризацию каталога землетрясений, т.е. удаление афтершоков и других зависимых событий. С учетом условия независимости магнитуд из получим вероятность непревышения заданного уровня сейсмических воздействий a от серии землетрясений в точке k в последующий промежуток времени T: Разумно предположить, что сейсмические источники независимы, и каждый из них живет своей жизнью. Опять-таки, в большой сейсмологии встречаются случаи, когда тектоническая активность одного разлома вызывает активизацию сейсмичности на другом. Тем не менее, из предположения независимости набора N сейсмических источников получим вероятность непревышения заданного уровня сейсмических воздействий a в нашем пункте «ожидания» в последующий промежуток времени T: Перейдем от вероятности непревышения в к вероятности превышения: Выражение является базовым для производства карт сейсмического районирования в вероятностном анализе сейсмической опасности. Разберем вкратце вероятность возникновения землетрясения P_k (s,M_i ). В сейсмическом районировании часто используется экспоненциальная Пуассоновская модель, то есть вероятность того, что в последующие T лет произойдет s землетрясений равна: где λ_k (M_i ) – частота возникновения землетрясений с магнитудой M_i в точке k. Как и положено сумма по всем s от нуля до бесконечности равна единице! Японские ученые по данным о палеоцунами сделали реконструкция исторических землетрясений. Как известно, цунами вызываются довольно сильными сейсмическими событиями, а их заплески сохраняются в геологической и морфологической истории побережья. По оценкам японцев в районе южных Курильских островов магнитуда максимально возможного землетрясения может быть не менее M=8.8. Как они считают, рассматриваемые события происходят не случайно, а периодично. Межсейсмический интервал лежит в диапазоне 340-380 лет, т.е. средний период повторяемости составляет 360 лет. Тогда частота возникновения землетрясений λ будет оцениваться как 1/360 год^-1. Давайте снова рассмотрим упрощенную модель сейсмического источника – в заданной точке заданной магнитуды (рис. 3). Нормативный интервал времени примем T=30 лет. Тогда очевидно, что λT << 1. Это означает, что в формуле можно ограничиться «первыми» вероятностями p0 и p1: Из следует, что в каждый момент времени возникновение землетрясения равновероятно. Например, по этой модели нашумевшее «мощнейшее» землетрясение возникнет в последующие 30 лет с вероятностью 0.083. Вероятность непревышения заданных сейсмических воздействий по формуле будет оцениваться как Искомая вероятность превышения согласно и задается как Раскладывая по степеням λT и оставляя только первые члены разложения, получим: Таким образом, при некоторых допущениях мы получили простую формулу для оценки нормативных сейсмических воздействий вероятностным методом. Осталась последняя деталь. Это закон затухания сильных движений грунта для Курильских островов. A – пиковое ускорение в см/с^2; D – «средняя» глубина плоскости разрыва (глубина центроида) в км; X – наикротчайшее расстояние до разрыва в км; Mw – моментная магнитуда; Для коровых землетрясений S_1=1, S_2=0, S_3=0; для межплитовых землетрясений S_1=0, S_2=1, S_3=0; для внутриплитовых S_1=0, S_2=0, S_3=1. Рисунок 4. Модель сейсмического источника на южных Курилах (источник) «Наше» мега-землетрясение ожидается на стыке двух плит, т.е. тип землетрясения – межплитовый. Японское мега-землетрясение Тохоку 2011 г., известное по трагедии на атомной станции Фукусима, произошло на глубине около 11 км. Поэтому и в нашем случае примем глубину очага D=11 км, а магнитуду Mw=8.8 (как предполагают японцы). На рис. 4 изображена пространственная модель ожидаемого на Курилах мега-землетрясения. Так, например для о. Шикотан наикротчайшее расстояние от погружающегося в сторону Курильских островов разлома до центра острова будет около 40 км, поэтому примем X=40 км. Теперь, когда все входные параметры определены, определим вероятность Pr(A≤a│m=8.8,r=40) из согласно закону затухания . Для этого надо немного повозиться, выражение привести к натуральному логарифму и т.д. В результате получим: g(m,r)=7.22, σ_ln PGA =0.62. Ниже, в табл. 2, представлены посчитанные значения вероятности. Таблица 2. Вероятности превышения заданных сейсмических воздействий Целью такого анализа является оценка вероятности превышения уровня движения грунта, а главный результат состоит в определении зависимости вероятности превышения от уровня движения, которая называется кривой опасности. Кривая опасности наглядно приведена на рис. 5 согласно данным из табл. 2. Из рис. 5 мы видим, что вероятность превышения 0.06 в течение ближайших 30 лет соответствует уровню сейсмических воздействий около 0.9g. Это больше 9 баллов. Такая оценка для Курильских островов является волне естественной и ожидаемой, если вспомнить, что здесь в 1994 году произошло крупное землетрясение, именуемое Шикотанским. Оно сопровождалось разрушениями сооружений, гибелью людей, волнами цунами и многочисленными оползнями. Интенсивность сотрясений на о. Шикотан составила от VIII до IX баллов по шкале MSK-64. Рисунок 5. Кривые опасности для о. Шикотан по модели сейсмического источника на южных Курилах по данным этого источника. Кроме Пуассоновской модели существуют модели возникновения землетрясений с «памятью», которые учитывают историю предшествующей сейсмичности. К ним относится Броуновская модель (Brownian Passage Time). Ее применяют японские коллеги при построении карт сейсмического районирования для хорошо изученных территорий. По их оценкам, вероятность возникновения мега-землетрясения в ближайшие 30 лет на южных Курилах составила от 0.07 до 0.4 (рис. 4). Представьте себе, что максимальное землетрясение происходит строго периодично – один раз в 1000 лет. И вот оно произошло, скажем, 20 лет назад, а мы собираемся в этом месте построить жилые здания, которые прослужат следующие 50 лет. За это время сильные события уже не произойдут, так как были только что, а следующее повторится не раньше, чем через 980 лет. Если такой факт периодичности установлен, то используется Броуновская модель. Тогда мы получим карты сейсмического районирования с более низкими значениями расчетной интенсивности сейсмических воздействий, и это на выходе удешевит строительство. Какую модель выбирать, решает не один специалист, а группа экспертов. Для расчета кривой опасности по Броуновской модели требуется больше времени и материалов. Однако мы примем для простоты, что вероятность возникновения одного землетрясения в последующие 30 лет нам известна и она равна p1, согласно донесению японских коллег. Тогда вероятность того, что ни одного события в ближайшие 30 лет не произойдет примем p0=1-p1. Окончательно вероятность превышения будет задаваться как Для максимальной вероятности возникновения мега-землетрясения 0.4 мы построили кривую опасности (рис. 5). Она показывает запредельные значения проектных сейсмических воздействий (рис. 5), более X баллов. В реальности мы не учитывали много моментов, касающихся грунтовых условий, характера затухания сейсмических воздействий от мега-землетрясений и т.д. Известно, что сейсмические воздействия от землетрясения с магнитудой Mw=9.0 не намного больше тех, что вызваны событиями с Mw=8.3. А это значит, что мы явно переоценили сейсмические воздействия по формуле . Тем не менее, представленный расчет позволяет почувствовать масштаб проблемы. Последнее. Почему японские сейсмологи дали вероятностную модель сейсмических источников на ближайшие 30 лет? В японских нормах приняты эксплуатационные сроки «жизни» зданий и сооружений 30 и 50 лет, в российских строительных правилах – 50 лет. Технология сейсмического районирования во всем мире (в том числе и у нас в стране) сводится к оценке сейсмических воздействий, которые будут превышены в течение 30 или 50 лет с заданной вероятностью. Для объектов нормальной ответственности (а это наши с вами жилые дома и офисы) строительными нормами задается вероятность превышения 0.1 в течение 50 лет. Для 30 лет задается вероятность 0.06 (это Япония и некоторые другие страны). Таким образом, японские сейсмологи приняли консервативную оценку сейсмической модели, которая будет использована при актуализации карт сейсмического районирования. Это подчеркивает высокую ответственность и культуру сейсмологических изысканий японских ученых. Это также говорит о том, что Земля не знает границ, и исследование природных явлений требует объединения усилий ученых из разных стран. Baker, J. W. An introduction to probabilistic seismic hazard analysis (PSHA) / J. W. Baker // Report for the US Nuclear Regulatory Commission, Version 1.3. 2008. Section 1. P. 5-27. Spectrogram-based models Решая проблему обобщающей способности мы интуитивно понимаем, что форма сигнала от локальных землетрясений сохраняется похожей что для Калифорнии, что для Дагестана (или любого другого региона). Консервативные геофизики скажут, что сигнал искажается грунтовыми условиями под конкретной станцией. Но ведь если мы отправим сейсмолога из Махачкалы в Лос-Анджелес и дадим ему в руки волновой поток, то он с уверенностью отметит все вступления. Нам нужно каким то образом наиболее четко выделить форму сигнала независимо от производителя прибора и места его локации. И тут нам на помощь приходит STFT. У нас под рукой временной ряд, так почему же не сделать спектрограмму и распознавать вступления уже с неё. К тому же эта техника активно применяется в процессинге аудио. Отлично! Теперь давайте сделаем модель CNN со спектрограммы. Если вы используете tensorflow то можете использовать готовое решение и положить вычисление STFT прямо в модель. Спектрограмма для низкочастотного «звука» сейсмических волн имеет свои характеристики, но в целом это не сильно отличается от примеров в документации. Здесь, наверное, нет ничего супер инновационного. Производительность CNN мы примерно знаем (и чуть позже протестируем). Но у нас в активе есть ещё трансформеры. Все про них уже знают, это сегодняшний мейнстрим, во многом за счёт высокой обобщающей способности и легкой адаптации модели к различным приложениям. Однако, эта технология глубокого обучения имеет существенный недостаток – вычислительная сложность O(n^2) в механизме внимания. В 2019 году была представлена архитектура Linformer, способная выполнять операции с вниманием за линейное время. Этот метод обладает некоторыми недостатками, одним из которых является существенное снижение точности. Работа «Rethinking Attention with Performers» (статья, код-эталон, видео-разбор) это попытка подобрать оценку к исходной матрице внимания, которую можно вычислить за линейное время. Механизм называется FAVOR+, он полностью совместим с оригинальной архитектурой. При распознавании картинок трансформерами изображения нормализуют так, что бы они были квадратными. Наши спектры не совсем квадратные, а имеют прямоугольную форму. Делать их квадратными не совсем правильно. Поэтому подправим немного архитектуру и подберём оптимальный размер патчей, а так же заменим механизм внимания на FAVOR+. Архитектура модели Seismo-Performer Stepnov, A.; Chernykh, V.; Konovalov, A. The Seismo-Performer: A Novel Machine Learning Approach for General and Efficient Seismic Phase Recognition from Local Earthquakes in Real Time. Sensors 2021, 21, 6290. https://doi.org/10.3390/s21186290 Выбор вступлений на записи всего землетрясения Другой подход — это подавать в модель запись всего землетрясения (30-60 секунд) с применением более сложной системы триггеров. Наиболее значимый результат показывает модель EQT. Несмотря на то что в названии модели присутствует слово Transformer, эта архитектура больше относится к CNN-based за счет подавляющего числа соответствующих блоков. Данный метод показывает хорошие результаты при сканировании непрерывных архивов, но он не подходит для обработки данных в режиме реального времени, потому что нам необходимо подождать, пока вся запись землетрясения поступит в дата центр. Итак, давайте сфокусируемся на подходе с короткими окнами и построим новую модель, которая будет иметь лучшую производительность по классификации и будет работать на CPU. Данные, обучающая и тестовая выборки Для того что бы правильно проверить обобщающую способность надо учить на одном наборе, а проверять на другом. Так и поступим. В качестве обучающей выборки возьмем самый большой на сегодняшний день датасэт волновых форм сейсмической сети Южной Калифорнии (размечен вручную). Архив содержит 4,5 миллиона сейсмограмм ровно разделённых по классам P/S-волн и Шум (P/S/N). Эти данные нормализованы и отфильтрованы, убраны отметки времени и станций, каждый сэмпл содержит три компоненты по 400 точек (4 секунды по 100Hz). В качестве тестовых данных мы будем использовать записи Сахалинской и Дегстанской сейсмических сетей. То есть обучать мы будем на Калифорнии а проверять на регионах в другом конце Земли — всё по честному. Тестовых данных будет не так много, потому что сети сейсмических станций не такие плотные как в Калифорнии, но для проверки вполне достаточно. Приводим данные к унифицированному виду как в обучающей выборке и готово. Хотя, на практике это было не так быстро, и отняло у нас кучу времени. Тестовый набор данных №1 Тестовый набор №2 Как выглядят исходные данные? Типичные 30 секунд велосиметра на Севере Сахалина (землетрясений здесь нет) Если мы посмотрим на запись прибора, то увидим, что в обычном режиме станция всегда что-то пишет. Представьте, что у вас очень чувствительный слух. Вы приложили ухо к земле и всё слышите: как течёт речка неподалёку, как бегут грунтовые воды, как шумят соседние населённые пункты. Если добавить к этому собственные колебания датчика, то мы получим картину, похожую на рисунок выше. Локальная сеть сейсмических станций, в зависимости от площади мониторинга, как правило, насчитывает 10 и более приборов. Все станции пишут непрерывные суточные архивы. Эти данные не идеальны. В непрерывном потоке могут быть пропуски из-за продолжительных обрывов связи. Датчики и регистраторы иногда выходят из строя и пишут совсем не то, что нужно, и так далее. Итак, представим, что данные у нас есть. Но прежде чем делать что-то новое (да ещё и c ML) давайте посмотрим какие проблемы возникают у сейсмологов на этапе выделения вступлений сейсмических волн. «Старый» STA/LTA Заголовок исходной публикации 1982 года и суть метода ftp://hazards.cr.usgs.gov/Eq_Effects/GeekPack/Procedures-Configs-Info/1_Dataloggers/K2-Altus/Sta-Lta. PDF Несмотря на то, что этот алгоритм появился в 80-х годах он до сих пор активно используется в сейсмологических центрах в различных вариантах. Его суть очень проста — отмечать время там, где энергия сигнала за короткий промежуток времени превышает фоновые значения которые рассчитывается на более длинном интервале. Этот алгоритм прост как автомат Калашникова, но у него есть существенные недостатки: Машинное обучение в сейсмологии Землетрясение M6.1 на Севере Сахалина https://eqalert.ru/#/events/QgpAn7OW Все хотя бы раз слышали про землетрясения. Это опасное природное явление которое может привести к разрушению зданий, возникновению цунами и гибели людей. С помощью составления каталогов землетрясений и анализа сейсмической активности человечество пытается минимизировать риски от наступления сейсмических событий. Основной источник данных в сейсмологии — это непрерывные записи движения грунта, которые регистрируют с помощью сейсмических станций. Для того что бы составить представительный каталог землетрясений необходимо определить времена вступлений сейсмических волн в непрерывном потоке, рассчитать параметры очага и выполнить оценку магнитуды. Каждый этап рутинной обработки сейсмологических данных это предмет отдельной статьи, но мы с вами посмотрим на самое интересное — распознавание сейсмических волн методами машинного обучения. Определение времён вступлений сейсмических волн до сих пор выполняется (или корректируется) операторами-сейсмологами. Автоматизация этой сложной задачи позволит полностью исключить ручной труд при непрерывной обработке данных любой сейсмической сети. При этом, необходима такая модель, которая с одной стороны могла обеспечить точность отметок вступлений на уровне человека, а с другой была эффективна на этапе вывода (эксплуатация на CPU). Возможно ли это? Давайте посмотрим! Основные этапы рутинной обработки сейсмологических данных Простой классификатор коротких записей Самое простое и интуитивное — это нарезать волновой ряд на короткие отрезки по 4-6 секунд. Каждый отдельный отрезок рассматриваем как образец (sample) который принадлежат к одному из классов: P-волна, S-волна или шум (Noise). Так как сейсмические волны имеют определённую характерную форму, по которой их узнаёт человек, то мы можем классифицировать наши данные как картинки, использую всю мощь соответствующих архитектур (например CNN). На этапе вывода волновой поток от сейсмостанции «нарезается» перекрывающимися окнами (что бы сигнал полностью попал в какое-то окно) и там, где вероятность выше заданного порога ставится отметка вступления. Наиболее удачная модель в этой области — это GPD. Ross, Z. E., Meier, M.-A., Hauksson, E., Heaton, T. H. (2018). Generalized Seismic Phase Detection with Deep Learning. ArXiv, 108(5A), 2894–2901. https://doi.org/10.1785/0120180080 Математическая модель укажет МЧС, где землетрясение будет ощущаться сильнее всего Учёные впервые разработали модель затухания толчков, позволяющую точнее разрабатывать карты сейсмической опасности. Их используют в строительстве, чтобы оценить, какую силу землетрясений должны выдерживать здания в конкретном регионе. Также модель может использоваться для генерации карт сотрясаемости, по которым МЧС сможет понять, где последствия землетрясения, вероятно, будут сильнее всего. Результаты исследования, поддержанного грантом Российского научного фонда (РНФ), опубликованы в журнале Geosciences. Для строительства любого здания нужно учитывать сейсмическую активность в регионе. В Чите (Забайкалье), где часто бывают землетрясения, можно строить панельные дома не выше пяти этажей, а в Москве, находящейся далеко от стыка литосферных плит, панельные дома часто строят девятиэтажными. При землетрясении от главного толчка распространяются горизонтальные колебания поверхности, которые затухают по определённому закону. Чтобы понять, какой толчок выдержит здание, нужно высчитать ускорение грунта. Учёные из Дальневосточного геологического института ДВО РАН (Владивосток) разработали математическую модель, которая позволит рассчитать предполагаемое инерционное ускорение грунта. При её создании авторы использовали базу данных всех землетрясений, произошедших на Сахалине с 2006 года по 2022 год. При этом в рассмотрение включили как объективные показатели, например магнитуду (энергию в очаге землетрясения), так и субъективные — авторы опросили 600 местных жителей, чувствовали ли они толчки в определённый день. Такой опрос позволил собрать данные в тех местах, в которых нет приборов, высчитывающих ускорение. Кроме того, модель учитывала тип земной коры и грунта в местах проведения исследования. Модель затухания толчков использует два основных показателя — геометрическое расхождение и характеристику сброшенного напряжения. Первый определяет, как распространяются сейсмические волны в пространстве. Также учитывается тип грунта: насколько сильно в нем затухают или усиливаются сейсмические ускорения, настолько слабее или сильнее могут быть воздействия на здание. Грунты делятся на три категории в зависимости от их состава и плотности. На Сахалине в месте проведения исследования грунты относятся к средней (второй) категории. В горах, на скалистых грунтах (первая категория) толчок ощущается чуть слабее, а в пустынях, на песках (третья категория) — сильнее. Второй показатель — сброшенное напряжение — зависит от того, активная или стабильная земная кора в этом месте, насколько сильное напряжение скопилось при движении плит. Там, где нет активного движения плит, земная кора стойкая, и показатель сброшенного напряжения выше, так как плиты двигались медленно, и напряжение между ними скапливалось сотни и тысячи лет. Так как модель учитывает все виды грунта и все типы сейсмической активности, она может применяться для любого региона. На основании вышеописанных показателей модель вычисляет ускорение грунта и определяет, насколько сильно будут ощущаться толчки в той или иной местности и землетрясения какой силы приведут к разрушению зданий. В результате можно создавать карты сейсмической опасности территорий, которые применяются при строительстве зданий. Кроме того, с помощью модели можно построить карту сотрясаемости. Ориентируясь на неё, МЧС понимает, в каком районе землетрясение, вероятно, вызвало максимальное воздействие и где колебания были сильнее всего. «Мы надеемся, что наша модель станет основной для нормирования сейсмических воздействий в строительной отрасли России. В дальнейшем мы будем развивать базу данных и дорабатывать математические модели, чтобы их оценки были более точными и не подверженными разбросу. В наших ближайших планах — создание новой магнитудной шкалы для оперативного определения энергии землетрясения, поскольку существующие шкалы требуют длительного накопления данных и часто недооценивают силу крупных землетрясений», — рассказывает руководитель проекта, поддержанного грантом РНФ, Алексей Коновалов, кандидат физико-математических наук, ведущий научный сотрудник лаборатории лавинных и селевых процессов Дальневосточного геологического института РАН. Тестирование производительности моделей Теперь обучим наши модели. Для этого стандартно поделим обучающий датасэт на тренировочный и валидационный (80/20). Поставим раннюю остановку там, где сходимость по валидационным данным (validation loss) не улучшается в течении 5 эпох. Учить будем несколько раз что бы исключить случайно хороший результат. Поэтому после каждой итерации фиксируем результат для тестовых данных и всё заново. Так как у нас три класса, то проверяем точность соответствующим образом. На этот счёт есть классная картинка от наших коллег из Калтэка. Что бы протестировать производительность на этапе эксплуатации запустим наши модели на непрерывных данных. Поделим суточный архив одной сейсмической станции на перекрывающиеся окошки со сдвигом в 40 миллисекунд, получим 214К сэмплов, прогоним их на CPU и замерим время вывода. Для того что бы исключить накладные расходы на обращение к файловой системе (и много к чему ещё) измерять будем только время вывода самих моделей. А результаты сравним с топовой моделью GPD. Тестирование моделей Stepnov, A.; Chernykh, V.; Konovalov, A. The Seismo-Performer: A Novel Machine Learning Approach for General and Efficient Seismic Phase Recognition from Local Earthquakes in Real Time. Sensors 2021, 21, 6290. https://doi.org/10.3390/s21186290 В таблице представлена общая точность для тестируемых моделей. Seismo-Performer и Spec-CNN это наши новые модели. G DP — это оригинальная модель, а GPD-fixed это переобученная и GPD на tf 2.5.0. При обучении на Калифорнийских данных (Panel A) мы видим лучший результат по точности как для тестовых так и для валидационных данных у архитектур на базе спектрограмм. Интересно, что если обучить все модели на специфичном Сахалинском наборе (Panel B), который содержит на несколько порядков меньше примеров, то наши новые модели существенно лучше распознают данные, которые они раньше не видели. В целом, можно сделать вывод, что и Seismo-Performer и Spec-CNN обладают лучшей обобщающей способностью, им нужно меньше данных для сходимости, так что наш скромный трюк со спектрами сработал. По производительность на этапе вывода лидирует Seismo-Performer: в 2,5 раза быстрее оригинально GPD и примерно на 35% быстрее своего соседа Spec-CNN. Здесь у нас чистая архитектура трансформера с оптимизацией FAVОR+ и минимальное количество параметров — всего 57k. По точности в абсолютных цифрах показатели немного ниже Spec-CNN, но +35% к скорости это существенно, с учётом того, что при эксплуатации это будет не одна станция а, например, 20. Если мы более подробно посмотрим на метрики производительности классификации, то увидим, что наши модели на основе спектров существенно лучше по показателю recall, а это значит, что они меньше «пропускают» полезный сигнал. Это очень важно на этапе эксплуатации, потому что ложные срабатывания всё же есть. Ложные срабатывания на реальных непрерывынх данных — это проблема всех существующих моделей. Дело в том при подготовке набора к обучению невозможно найти абсолютно все граничные случаи, когда сигнал является шумом, но он похож на реальное вступление. В качестве временного решения мы можем повысить порог значения SoftMax для класса при котором он будет считаться точным срабатыванием. Если у вас хороший recall, то вы можете сделать порог повыше и получить меньше пропусков и почти полное отсутсвие ложных срабатываний. Это, можно сказать, конечный результат. Красные линии это отметки оператора. Звёздочки, это то что нашли модели (практически в одном месте для всех примеров). В качестве времени вступление выбирается «окошко» в котором вероятность на класс максимальна относительно соседних окон и выше заданного порога. Точность отметки в районе погрешности отметки оператора. Deep learning Итак, мы с вами добрались до самого интересного — это методы машинного обучения. Кроме очевидных преимуществ этого подхода, таких как распознавание именно формы сигнала и скорость вывода, стоит отметить открытые вопросы: Давайте заглянем в научные работы и посмотрим как там обстоят дела. Если исключить совсем пионерские работы, то основная масса научных статей на эту тему опубликована в последние пять лет. Нужно дополнительно очертить наше поле исследований: мы будем говорить о локальных землетрясениях, то есть о таких событиях, когда расстояние от очага до сейсмической станции не превышает 300 километров. Выделять мы будем P и S волны от локальных землетрясений. Сейчас можно уверенно говорить о существовании двух подходов к этой задаче. Кросс-корреляция и сопоставление шаблонов Этот метод начал активно применяться с начала 2000-х когда вычислительные мощности позволили выполнить это. Алгоритм способен находить очень слабые землетрясения. Кросс-корреляция активно используется для восстановления афтершоковых последовательностей. Дело в том, что когда происходит сильное землетрясение то следом за главным событием обычно происходят тысячи более слабых землетрясений. Если в качестве мастер-события задать главный толчок, то тогда поиск других землетрясений из этой же очаговой зоны будет успешен. Однако, у этого метода есть главный недостаток: нет мастер-события — нет результата. Если землетрясение произойдет в другой очаговой зоне, то мы ничего не увидим. То есть применять этот алгоритм для решения наших проблем затруднительно, так как мы не знаем заранее где возникнет сейсмическое событие. Заключение Мы с вами посмотрели специфичную задачу из области наук о Земле. На выходе мы получили ML-модели которые отмечают вступления сейсмических волн на уровне оператора-сейсмолога. За счёт применения спектрограмм у нас получилось сделать сигнал более четким и улучшить обобщающую способность. А современные наработки из NLP позволили сделать очень быструю модель, которая может работать на CPU и готова к внедрению в сейсмологических дата центрах. Оригинальная работа, репозиторий на GitHub c данными и плейбуками. Спасибо, что дочитали до конца.
- Spectrogram-based models
- Выбор вступлений на записи всего землетрясения
- Данные, обучающая и тестовая выборки
- Как выглядят исходные данные?
- «Старый» STA/LTA
- Машинное обучение в сейсмологии
- Простой классификатор коротких записей
- Математическая модель укажет МЧС, где землетрясение будет ощущаться сильнее всего
- Тестирование производительности моделей
- Deep learning
- Кросс-корреляция и сопоставление шаблонов
- Заключение
Рост числа сейсмических станций
Когда-то раньше сейсмические станции были дорогими и сложными в обслуживании. Сейчас приборы на базе raspberry может позволить себе не только любая геофизическая компания, но и самостоятельные исследователи или просто увлечённые этой темой люди. Любому инженеру понятно что чем больше приборов, тем больше данных, и, значит, точность расчётов будет лучше. Хорошо! А теперь давайте посмотрим, как выглядит 15 минут записи 28 станций.
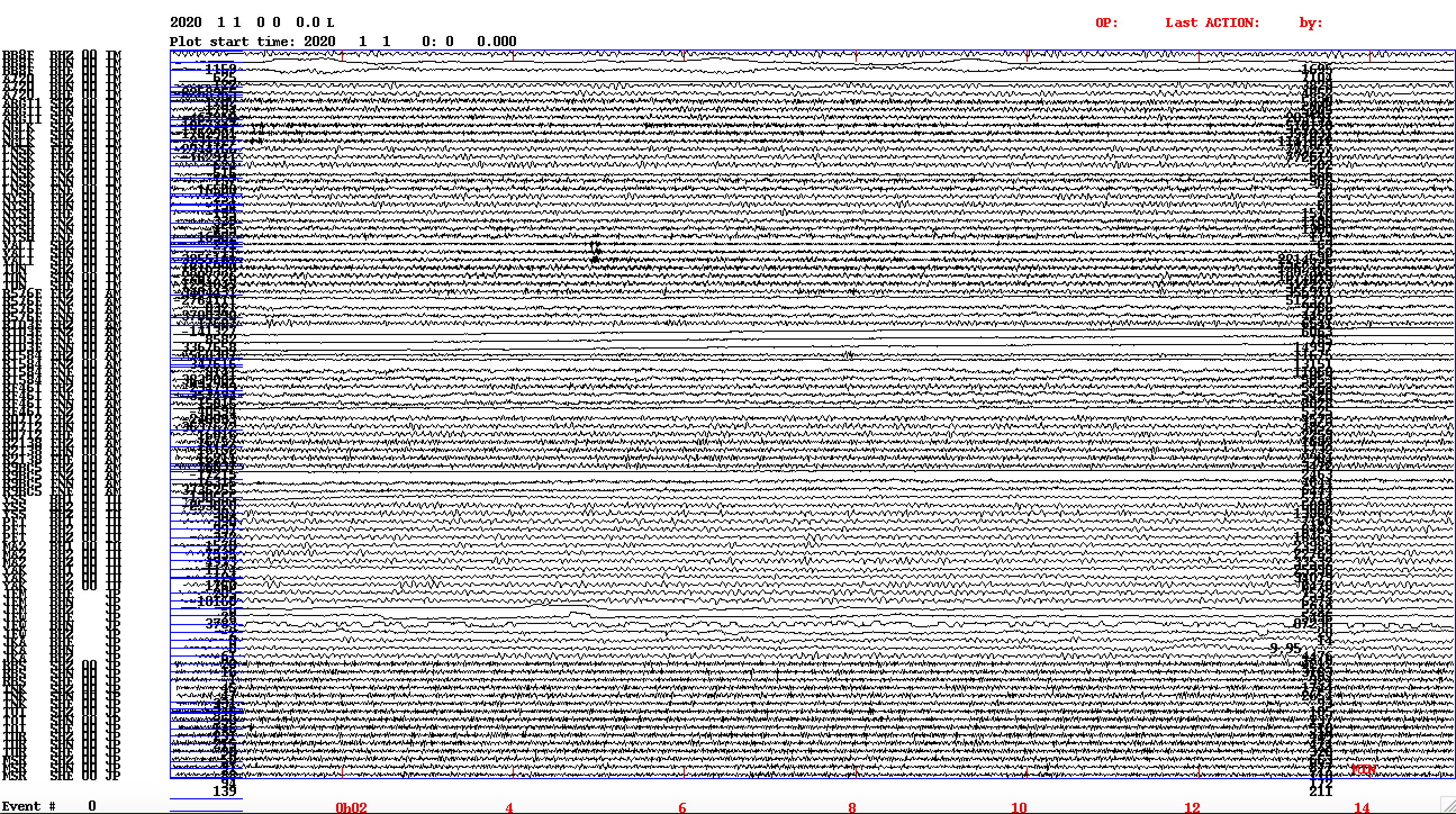
1 января 2020 года, 15 минут данных, 28 станций, 92 канала
Понятно, что какие то сильные землетрясения на такой развёртке будет видно, но слабые события тут уже разглядеть не получится. Нужно учитывать что оператор, который просматривает поток глазами, должен перекрывающими окнами по 15 минут просмотреть целые сутки. При 28 активных станциях для мониторинга Сахалина уже нужно делить сейсмометры на две группы (Север и Юг острова) и просматривать каждую группу отдельно. При этом, очевидно, что 28 станций это мало и через 3-5 лет их будет в два раза больше.
Много импульсного шума
Фоновый шум мы уже разобрали, но дело в том, что это не весь шум который бывает. Если станция расположена вблизи населённого пункта, то мы видим на записях все проявления индустриальной активности: ходьба людей рядом со станцией, работа снегоуборочной техники, движение автотранспорта поблизости и так далее. Если у вас таких «шумных» станций много, то выглядит это примерно так:
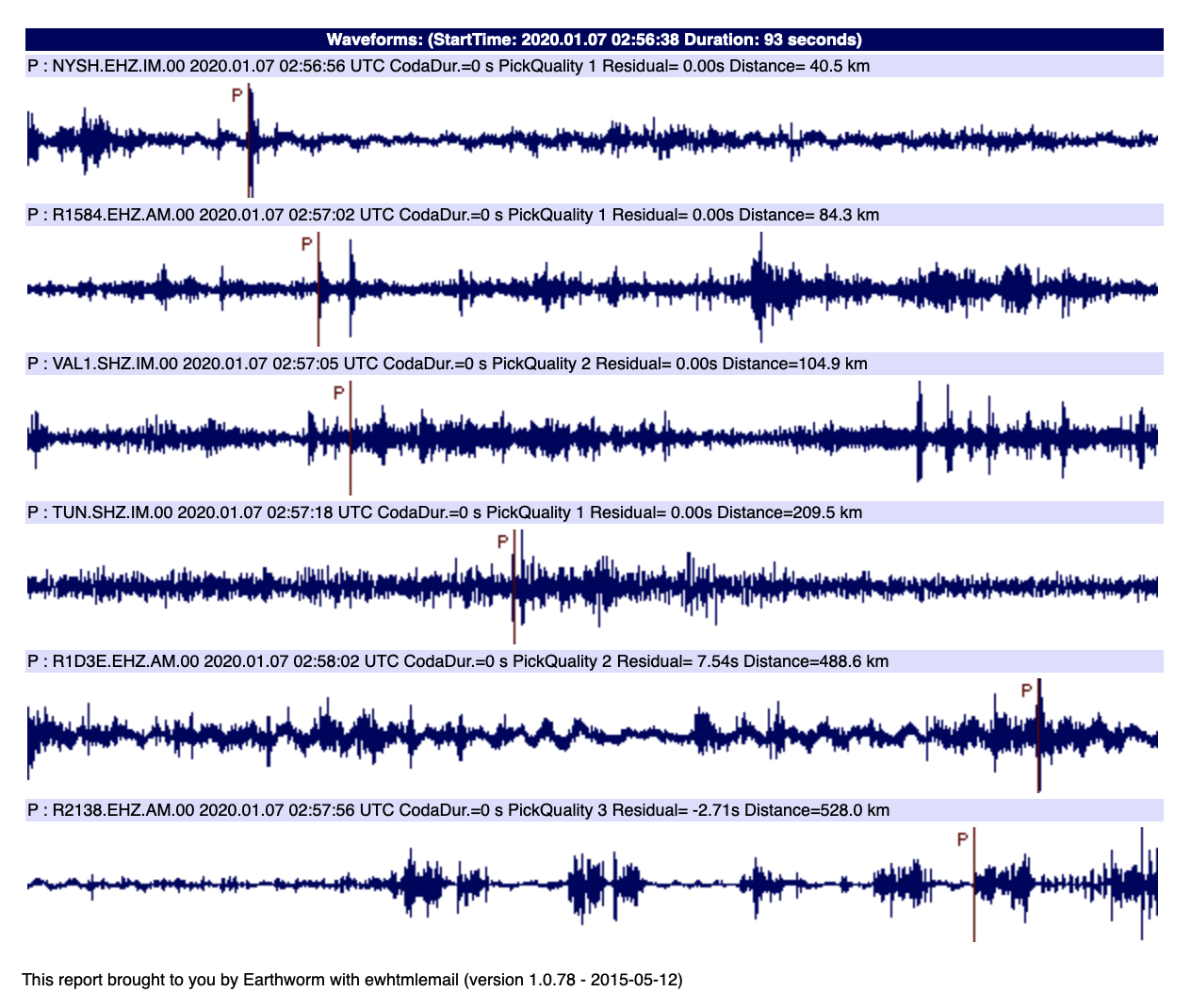
Выглядит как слабое землетрясение, но это коррелированный шум.
Расстояние между станциями от 25 до 400 км.
На примере выше алгоритм STA/LTA (о нем чуть позже) ошибочно расставил отметки вступления. Эти отметки были поданы дальше в алгоритм локации, который по пороговому значению среднеквадратичной невязки посчитал что это реальное землетрясение. Но на самом деле нет. Это просто грузовики так одновременно проехали или что-то там ещё в близи станций случилось. Такой импульсный шум сильно усложняет обработку. Бывают всплески очень похожие на вступления сейсмической волны и оператор всегда тратит дополнительное время при появлении импульсного шума.
Вероятностный анализ сейсмической опасности
Время на прочтение
Причиной написания этой статьи стала распространенная рядом СМИ информация о прогнозе «мощнейшего» землетрясения, которое может произойти в ближайшие 30 лет в Японии и на Курилах с вероятностью до 40%. Ссылались журналисты на японских ученых. Нам удалось найти оригинал статьи, откуда, по всей видимости, и взяты сведения. Она была опубликована 20 декабря в Japan News и сейчас находится в платном архиве, но у нас есть замечательный ресурс wayback machine.
У каждого землетрясения есть своя магнитуда M. Это величина, которая характеризует силу (размер разрыва, энергию и т.д.) в очаге. Не путать с баллом! Балл – это уже проявление сотрясаемости на поверхности, то есть ощущаемость. Чем ближе к эпицентру, тем интенсивнее колеблется поверхность Земли, тем выше уровень сейсмических воздействий, а удаляясь от эпицентра, сейсмические сигналы затухают. Это фундаментальное свойство, присущее всем сигналам в сплошной среде. Назовем его законом затухания сейсмических воздействий. Очевидно, что разрушает здание не магнитуда, а пиковые ускорения грунта, которые превышают некоторый предельный уровень, заложенный при проектировании и строительстве (рис. 1).

где c_1, c_2, c_3, c_4, c_5, c_6, c_7 – регрессионные коэффициенты, а F и S описывают соответственно зависимость от типа разлома (Fault) и характеристик грунта (Soil).

Рисунок 2. Кривая затухания пиковых ускорений грунта с расстоянием для землетрясения с магнитудой M=5.8: 1 – измеренные значения, 2 – региональная регрессия, 3 – доверительный интервал ±σ, 4 – плотностная функция стандартного нормального распределения натурального логарифма пикового ускорения на расстоянии 10 км от очага, 5 – уровень пиковых ускорений 0.7g.
Тогда из сделанных выше предположений относительно логнормального распределения пикового ускорения грунта следует, что из всех событий магнитуды m, происходящих на расстоянии r от рассматриваемого пункта, доля тех событий, что не вызовет сейсмические воздействия, превышающие ускорение a, есть
Таким образом, вероятность непревышения заданного уровня сейсмических воздействий a от сейсмического события с магнитудой m на расстоянии r будет полностью задаваться функцией распределения стандартной нормальной величины. Обозначим эту вероятность как Pr(A≤a│m,r). Тогда в соответствии с определением
можно записать:
Графическая интерпретация формул
—
показана на рис. 2. Видно, что регрессия описывает измеренные значения пиковых ускорений грунта. Все точки относятся к одному землетрясению. Точнее говоря, сама регрессия построена по большому набору эмпирических данных разных землетрясений, но для простоты изложения приведены графики для землетрясения с магнитудой M=5.8. Скажем, вблизи Невельска (рис. 1) произошла серия землетрясений по магнитуде близких к M~6, вызвавшая разрушения в городе.
На рис. 2 виден разброс значений пикового ускорения, который определяет стандартную ошибку σ=0.783 из
. Натуральный логарифм пикового ускорения грунта для точек m=5.8 и r=10 км равен g(m,r)=4.868 (PGA=125 см/сек^2). Сейсмические воздействия с пиковым ускорением 0.7g (687 см/сек^2) соответствую ln a=6.532. Тогда вероятность того, что сейсмические воздействия A, вызванные землетрясением с магнитудой m=5.8 на расстоянии r=10 км, не превысят 0.7g (IX баллов) равна (см. Приложение):
Здания не строятся на бесконечное время эксплуатации. У всего есть свой срок службы, и он определяется временем T.

Рисунок 3. Схематическая иллюстрация сейсмических источников.
В каком же случае воздействия от землетрясения с магнитудой M_i, очаг которого располагается в точке k (рис. 3), не превысят в заданном пункте величину ускорения a в течение последующего промежутка времени T? Первый ответ на такой длинный вопрос очевиден: если вообще не произойдет ни одного землетрясения за рассматриваемый временной интервал. Второй случай, менее очевиден: если произойдет одно землетрясение, но по определенному в
закону затухания оно не вызовет ожидаемых сейсмических воздействий. Вообще за время T может произойти хоть два землетрясения или три или вообще Ns. Перефразируем сказанное в терминах вероятности.
Примем упрощенную модель, в которой некоторая точка генерирует землетрясения только одной магнитуды. Посмотрим на табл. 1. В ней показаны различные исходы, при которых сейсмические воздействия не будут превышены: ни одного сейсмического события (0), одно
, два (1 + 1), три (1 + 1 + 1) и т.д. Вероятность возникновения одного события в течение времени T равна p1, двух – p2, трех – p3 и т.д., ни одного – соответственно p0. Естественно, рассматриваемое множество исходов является полным, т.е. других вариантов нет:
Вероятность того, что колебания от землетрясения заданной магнитуды не превысят заданное сейсмической воздействие в заданном пункте, обозначим как Pr, которая полностью задается через
. Тогда вероятность того, что колебания от двух землетрясений не превысят заданное сейсмической воздействие, равна Pr*Pr, трех – Pr*Pr*Pr и т.д. При отсутствии землетрясений, очевидно, что вероятность непревышения равна 1. Таким образом, полная вероятность P того, что в течение времени T сейсмические воздействия в заданном пункте не будут превышены:
Таблица 1. Вероятностные модели источника землетрясений заданной магнитуды в заданной точке.
Тогда вероятность непревышения заданного уровня сейсмических воздействий a от сейсмического события с магнитудой M_i в точке k (рис. 3) в последующий промежуток времени T будет задаваться по аналогии с
:
где R_k – расстояние от очага землетрясения в точке k до пункта, в котором мы ожидаем сейсмические воздействия.
Дальше – проще. Необходимо рассмотреть независимые реализации магнитуд M_i. Конечно, в большой сейсмологии есть исключения. Например, когда сильное землетрясение вызывает серию афтершоков (или другими словами повторные события с магнитудой чуть меньше, чем у главного события). Но для этого производят так называемую декластеризацию каталога землетрясений, т.е. удаление афтершоков и других зависимых событий.
С учетом условия независимости магнитуд из
получим вероятность непревышения заданного уровня сейсмических воздействий a от серии землетрясений в точке k в последующий промежуток времени T:
Разумно предположить, что сейсмические источники независимы, и каждый из них живет своей жизнью. Опять-таки, в большой сейсмологии встречаются случаи, когда тектоническая активность одного разлома вызывает активизацию сейсмичности на другом. Тем не менее, из предположения независимости набора N сейсмических источников получим вероятность непревышения заданного уровня сейсмических воздействий a в нашем пункте «ожидания» в последующий промежуток времени T:
Перейдем от вероятности непревышения в
к вероятности превышения:
Выражение
является базовым для производства карт сейсмического районирования в вероятностном анализе сейсмической опасности.
Разберем вкратце вероятность возникновения землетрясения P_k (s,M_i ). В сейсмическом районировании часто используется экспоненциальная Пуассоновская модель, то есть вероятность того, что в последующие T лет произойдет s землетрясений равна:
где λ_k (M_i ) – частота возникновения землетрясений с магнитудой M_i в точке k. Как и положено сумма
по всем s от нуля до бесконечности равна единице!
Японские ученые по данным о палеоцунами сделали реконструкция исторических землетрясений. Как известно, цунами вызываются довольно сильными сейсмическими событиями, а их заплески сохраняются в геологической и морфологической истории побережья. По оценкам японцев в районе южных Курильских островов магнитуда максимально возможного землетрясения может быть не менее M=8.8. Как они считают, рассматриваемые события происходят не случайно, а периодично. Межсейсмический интервал лежит в диапазоне 340-380 лет, т.е. средний период повторяемости составляет 360 лет. Тогда частота возникновения землетрясений λ будет оцениваться как 1/360 год^-1.
Давайте снова рассмотрим упрощенную модель сейсмического источника – в заданной точке заданной магнитуды (рис. 3). Нормативный интервал времени примем T=30 лет. Тогда очевидно, что λT << 1. Это означает, что в формуле
можно ограничиться «первыми» вероятностями p0 и p1:
Из
следует, что в каждый момент времени возникновение землетрясения равновероятно. Например, по этой модели нашумевшее «мощнейшее» землетрясение возникнет в последующие 30 лет с вероятностью 0.083.
Вероятность непревышения заданных сейсмических воздействий по формуле
будет оцениваться как
Искомая вероятность превышения согласно
и
задается как
Раскладывая
по степеням λT и оставляя только первые члены разложения, получим:
Таким образом, при некоторых допущениях мы получили простую формулу для оценки нормативных сейсмических воздействий вероятностным методом. Осталась последняя деталь. Это закон затухания сильных движений грунта для Курильских островов.
A – пиковое ускорение в см/с^2; D – «средняя» глубина плоскости разрыва (глубина центроида) в км; X – наикротчайшее расстояние до разрыва в км; Mw – моментная магнитуда;
Для коровых землетрясений S_1=1, S_2=0, S_3=0; для межплитовых землетрясений S_1=0, S_2=1, S_3=0; для внутриплитовых S_1=0, S_2=0, S_3=1.

Рисунок 4. Модель сейсмического источника на южных Курилах (источник)
«Наше» мега-землетрясение ожидается на стыке двух плит, т.е. тип землетрясения – межплитовый. Японское мега-землетрясение Тохоку 2011 г., известное по трагедии на атомной станции Фукусима, произошло на глубине около 11 км. Поэтому и в нашем случае примем глубину очага D=11 км, а магнитуду Mw=8.8 (как предполагают японцы). На рис. 4 изображена пространственная модель ожидаемого на Курилах мега-землетрясения. Так, например для о. Шикотан наикротчайшее расстояние от погружающегося в сторону Курильских островов разлома до центра острова будет около 40 км, поэтому примем X=40 км. Теперь, когда все входные параметры определены, определим вероятность Pr(A≤a│m=8.8,r=40) из
согласно закону затухания
. Для этого надо немного повозиться, выражение
привести к натуральному логарифму и т.д. В результате получим: g(m,r)=7.22, σ_ln PGA =0.62. Ниже, в табл. 2, представлены посчитанные значения вероятности.
Таблица 2. Вероятности превышения заданных сейсмических воздействий
Целью такого анализа является оценка вероятности превышения уровня движения грунта, а главный результат состоит в определении зависимости вероятности превышения от уровня движения, которая называется кривой опасности. Кривая опасности наглядно приведена на рис. 5 согласно данным из табл. 2. Из рис. 5 мы видим, что вероятность превышения 0.06 в течение ближайших 30 лет соответствует уровню сейсмических воздействий около 0.9g. Это больше 9 баллов. Такая оценка для Курильских островов является волне естественной и ожидаемой, если вспомнить, что здесь в 1994 году произошло крупное землетрясение, именуемое Шикотанским. Оно сопровождалось разрушениями сооружений, гибелью людей, волнами цунами и многочисленными оползнями. Интенсивность сотрясений на о. Шикотан составила от VIII до IX баллов по шкале MSK-64.

Рисунок 5. Кривые опасности для о. Шикотан по модели сейсмического источника на южных Курилах по данным этого источника.
Кроме Пуассоновской модели существуют модели возникновения землетрясений с «памятью», которые учитывают историю предшествующей сейсмичности. К ним относится Броуновская модель (Brownian Passage Time). Ее применяют японские коллеги при построении карт сейсмического районирования для хорошо изученных территорий. По их оценкам, вероятность возникновения мега-землетрясения в ближайшие 30 лет на южных Курилах составила от 0.07 до 0.4 (рис. 4).
Представьте себе, что максимальное землетрясение происходит строго периодично – один раз в 1000 лет. И вот оно произошло, скажем, 20 лет назад, а мы собираемся в этом месте построить жилые здания, которые прослужат следующие 50 лет. За это время сильные события уже не произойдут, так как были только что, а следующее повторится не раньше, чем через 980 лет. Если такой факт периодичности установлен, то используется Броуновская модель. Тогда мы получим карты сейсмического районирования с более низкими значениями расчетной интенсивности сейсмических воздействий, и это на выходе удешевит строительство. Какую модель выбирать, решает не один специалист, а группа экспертов.
Для расчета кривой опасности по Броуновской модели требуется больше времени и материалов. Однако мы примем для простоты, что вероятность возникновения одного землетрясения в последующие 30 лет нам известна и она равна p1, согласно донесению японских коллег. Тогда вероятность того, что ни одного события в ближайшие 30 лет не произойдет примем p0=1-p1. Окончательно вероятность превышения будет задаваться как
Для максимальной вероятности возникновения мега-землетрясения 0.4 мы построили кривую опасности (рис. 5). Она показывает запредельные значения проектных сейсмических воздействий (рис. 5), более X баллов. В реальности мы не учитывали много моментов, касающихся грунтовых условий, характера затухания сейсмических воздействий от мега-землетрясений и т.д. Известно, что сейсмические воздействия от землетрясения с магнитудой Mw=9.0 не намного больше тех, что вызваны событиями с Mw=8.3. А это значит, что мы явно переоценили сейсмические воздействия по формуле
. Тем не менее, представленный расчет позволяет почувствовать масштаб проблемы.
Последнее. Почему японские сейсмологи дали вероятностную модель сейсмических источников на ближайшие 30 лет? В японских нормах приняты эксплуатационные сроки «жизни» зданий и сооружений 30 и 50 лет, в российских строительных правилах – 50 лет. Технология сейсмического районирования во всем мире (в том числе и у нас в стране) сводится к оценке сейсмических воздействий, которые будут превышены в течение 30 или 50 лет с заданной вероятностью. Для объектов нормальной ответственности (а это наши с вами жилые дома и офисы) строительными нормами задается вероятность превышения 0.1 в течение 50 лет. Для 30 лет задается вероятность 0.06 (это Япония и некоторые другие страны).
Таким образом, японские сейсмологи приняли консервативную оценку сейсмической модели, которая будет использована при актуализации карт сейсмического районирования. Это подчеркивает высокую ответственность и культуру сейсмологических изысканий японских ученых. Это также говорит о том, что Земля не знает границ, и исследование природных явлений требует объединения усилий ученых из разных стран.

Baker, J. W. An introduction to probabilistic seismic hazard analysis (PSHA) / J. W. Baker // Report for the US Nuclear Regulatory Commission, Version 1.3. 2008. Section 1. P. 5-27.
Spectrogram-based models
Решая проблему обобщающей способности мы интуитивно понимаем, что форма сигнала от локальных землетрясений сохраняется похожей что для Калифорнии, что для Дагестана (или любого другого региона). Консервативные геофизики скажут, что сигнал искажается грунтовыми условиями под конкретной станцией. Но ведь если мы отправим сейсмолога из Махачкалы в Лос-Анджелес и дадим ему в руки волновой поток, то он с уверенностью отметит все вступления. Нам нужно каким то образом наиболее четко выделить форму сигнала независимо от производителя прибора и места его локации. И тут нам на помощь приходит STFT. У нас под рукой временной ряд, так почему же не сделать спектрограмму и распознавать вступления уже с неё. К тому же эта техника активно применяется в процессинге аудио.
Отлично! Теперь давайте сделаем модель CNN со спектрограммы. Если вы используете tensorflow то можете использовать готовое решение и положить вычисление STFT прямо в модель. Спектрограмма для низкочастотного «звука» сейсмических волн имеет свои характеристики, но в целом это не сильно отличается от примеров в документации.
Здесь, наверное, нет ничего супер инновационного. Производительность CNN мы примерно знаем (и чуть позже протестируем). Но у нас в активе есть ещё трансформеры. Все про них уже знают, это сегодняшний мейнстрим, во многом за счёт высокой обобщающей способности и легкой адаптации модели к различным приложениям. Однако, эта технология глубокого обучения имеет существенный недостаток – вычислительная сложность O(n^2) в механизме внимания. В 2019 году была представлена архитектура Linformer, способная выполнять операции с вниманием за линейное время. Этот метод обладает некоторыми недостатками, одним из которых является существенное снижение точности. Работа «Rethinking Attention with Performers» (статья, код-эталон, видео-разбор) это попытка подобрать оценку к исходной матрице внимания, которую можно вычислить за линейное время. Механизм называется FAVOR+, он полностью совместим с оригинальной архитектурой.
При распознавании картинок трансформерами изображения нормализуют так, что бы они были квадратными. Наши спектры не совсем квадратные, а имеют прямоугольную форму. Делать их квадратными не совсем правильно. Поэтому подправим немного архитектуру и подберём оптимальный размер патчей, а так же заменим механизм внимания на FAVOR+.
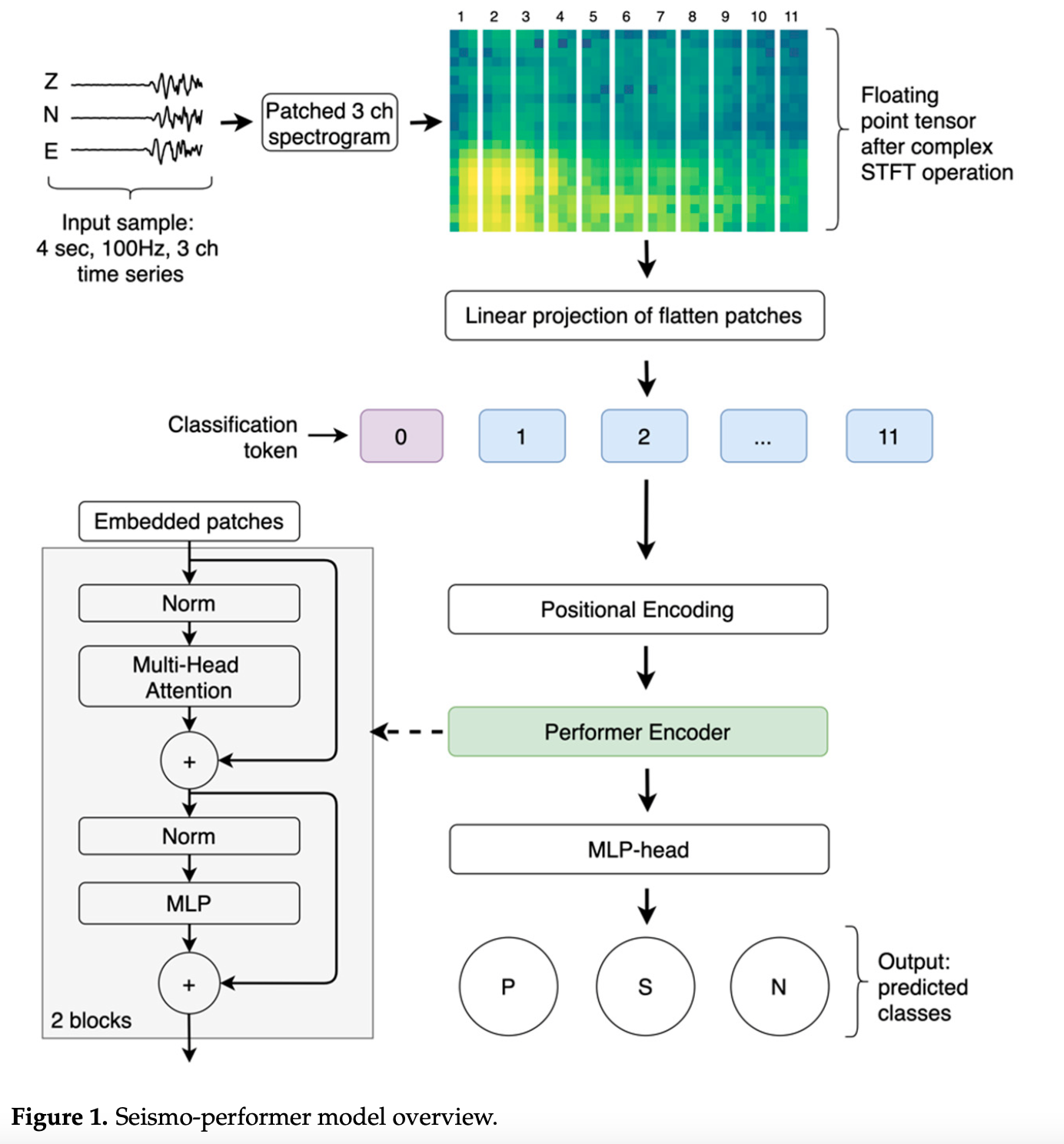
Архитектура модели Seismo-Performer
Stepnov, A.; Chernykh, V.; Konovalov, A. The Seismo-Performer: A Novel Machine Learning Approach for General and Efficient Seismic Phase Recognition from Local Earthquakes in Real Time. Sensors 2021, 21, 6290. https://doi.org/10.3390/s21186290
Выбор вступлений на записи всего землетрясения
Другой подход — это подавать в модель запись всего землетрясения (30-60 секунд) с применением более сложной системы триггеров. Наиболее значимый результат показывает модель EQT. Несмотря на то что в названии модели присутствует слово Transformer, эта архитектура больше относится к CNN-based за счет подавляющего числа соответствующих блоков. Данный метод показывает хорошие результаты при сканировании непрерывных архивов, но он не подходит для обработки данных в режиме реального времени, потому что нам необходимо подождать, пока вся запись землетрясения поступит в дата центр.
Итак, давайте сфокусируемся на подходе с короткими окнами и построим новую модель, которая будет иметь лучшую производительность по классификации и будет работать на CPU.
Данные, обучающая и тестовая выборки
Для того что бы правильно проверить обобщающую способность надо учить на одном наборе, а проверять на другом. Так и поступим. В качестве обучающей выборки возьмем самый большой на сегодняшний день датасэт волновых форм сейсмической сети Южной Калифорнии (размечен вручную). Архив содержит 4,5 миллиона сейсмограмм ровно разделённых по классам P/S-волн и Шум (P/S/N). Эти данные нормализованы и отфильтрованы, убраны отметки времени и станций, каждый сэмпл содержит три компоненты по 400 точек (4 секунды по 100Hz).
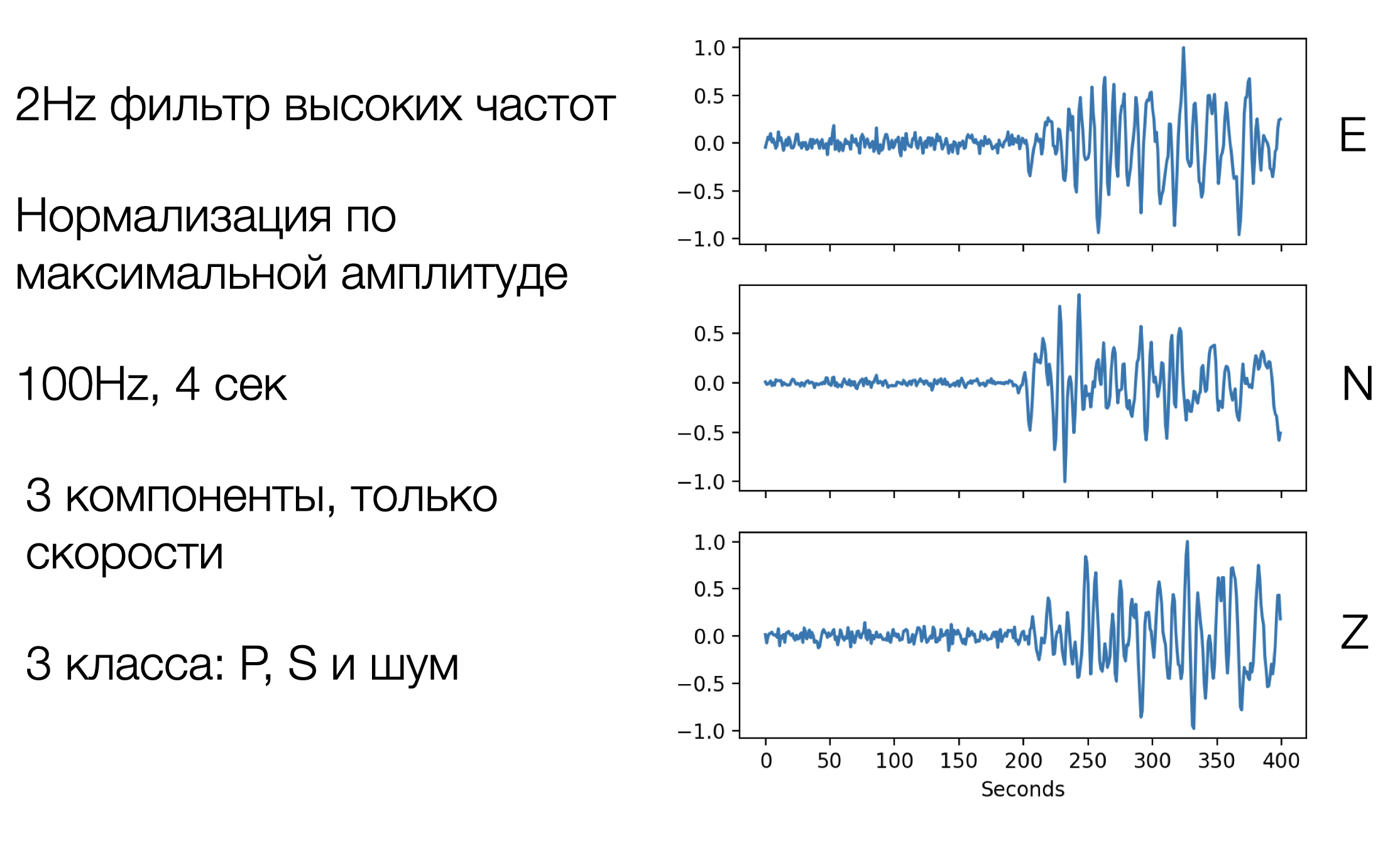
В качестве тестовых данных мы будем использовать записи Сахалинской и Дегстанской сейсмических сетей. То есть обучать мы будем на Калифорнии а проверять на регионах в другом конце Земли — всё по честному. Тестовых данных будет не так много, потому что сети сейсмических станций не такие плотные как в Калифорнии, но для проверки вполне достаточно. Приводим данные к унифицированному виду как в обучающей выборке и готово. Хотя, на практике это было не так быстро, и отняло у нас кучу времени.
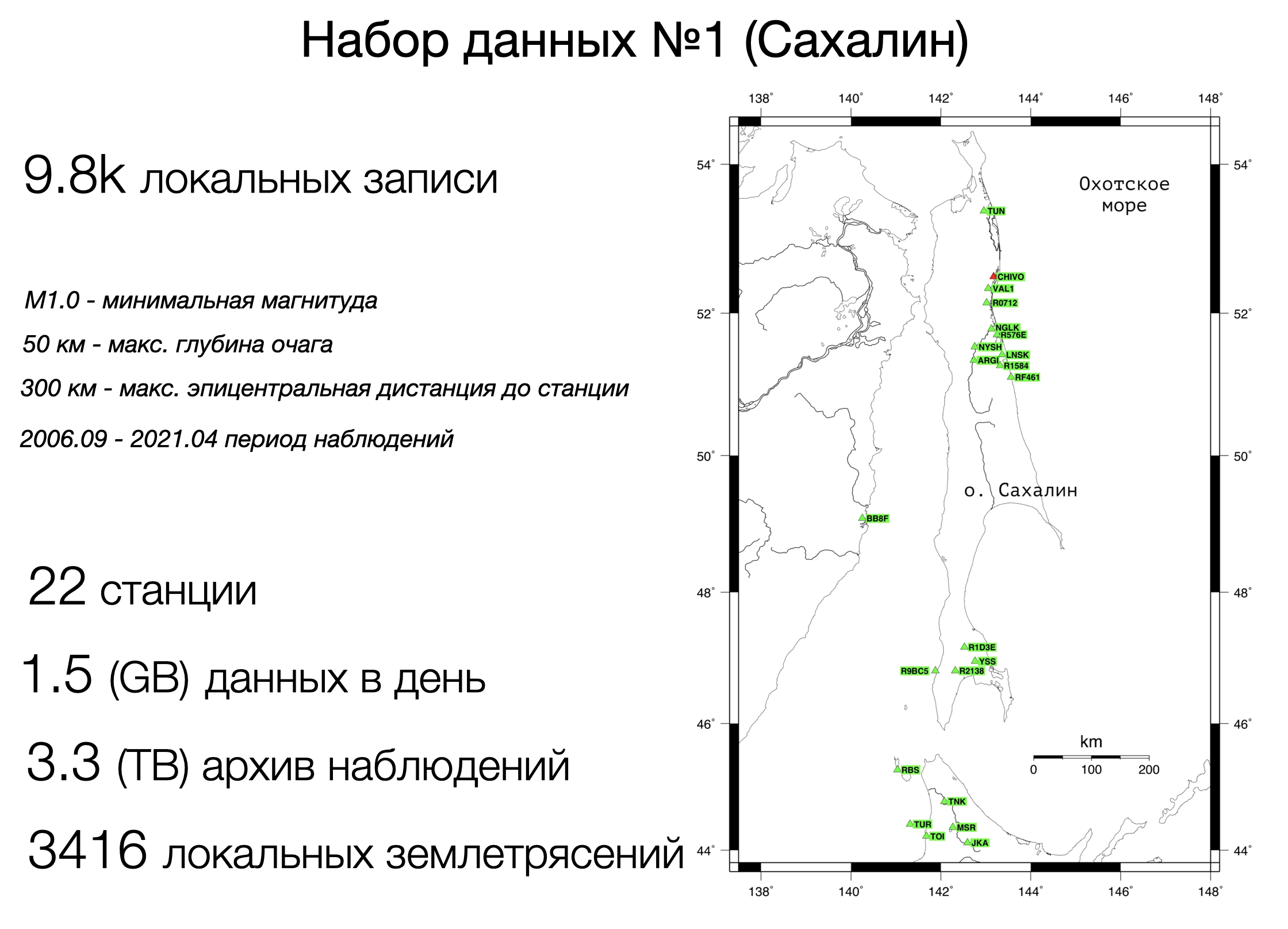
Тестовый набор данных №1
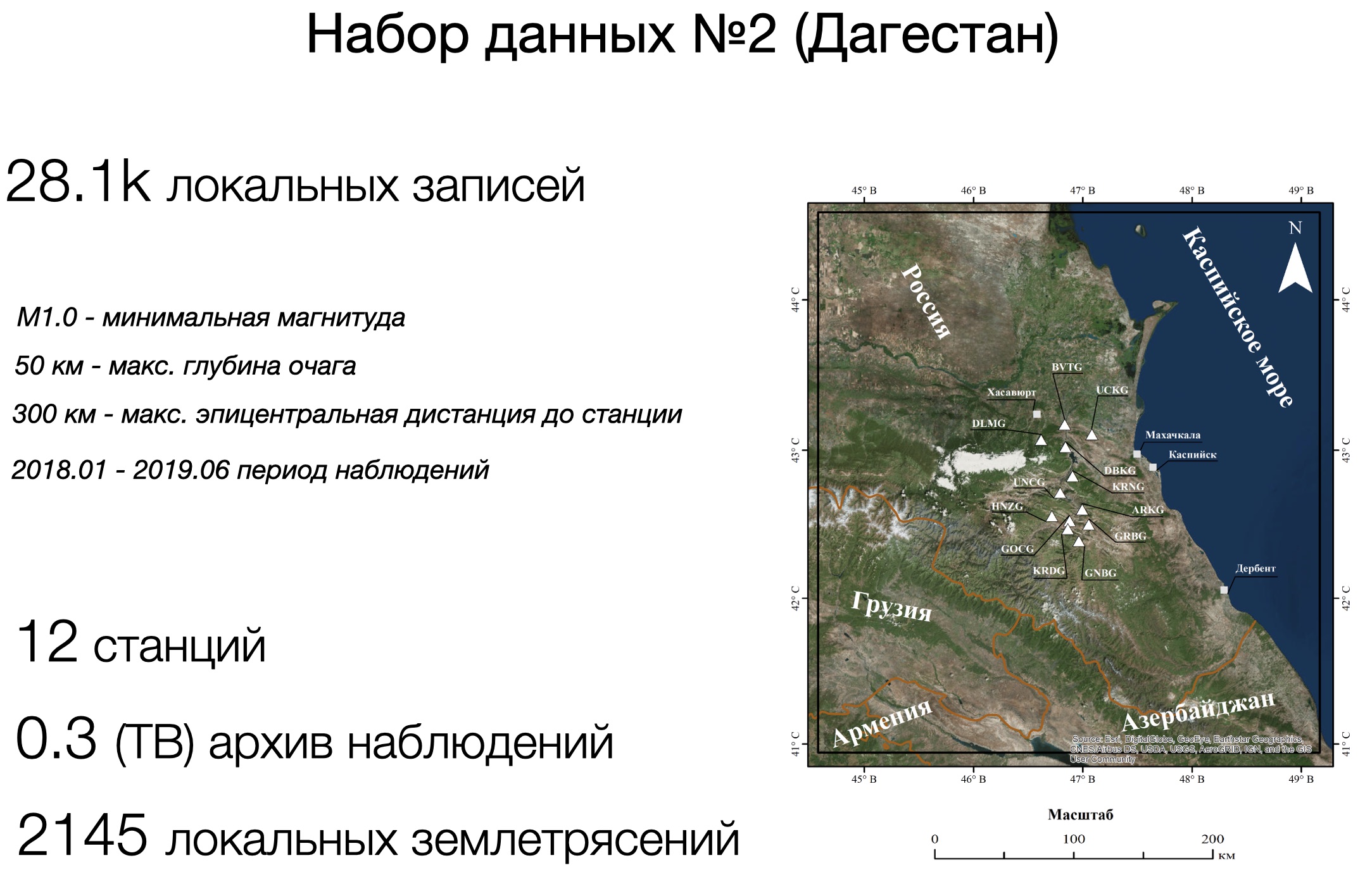
Тестовый набор №2
Как выглядят исходные данные?
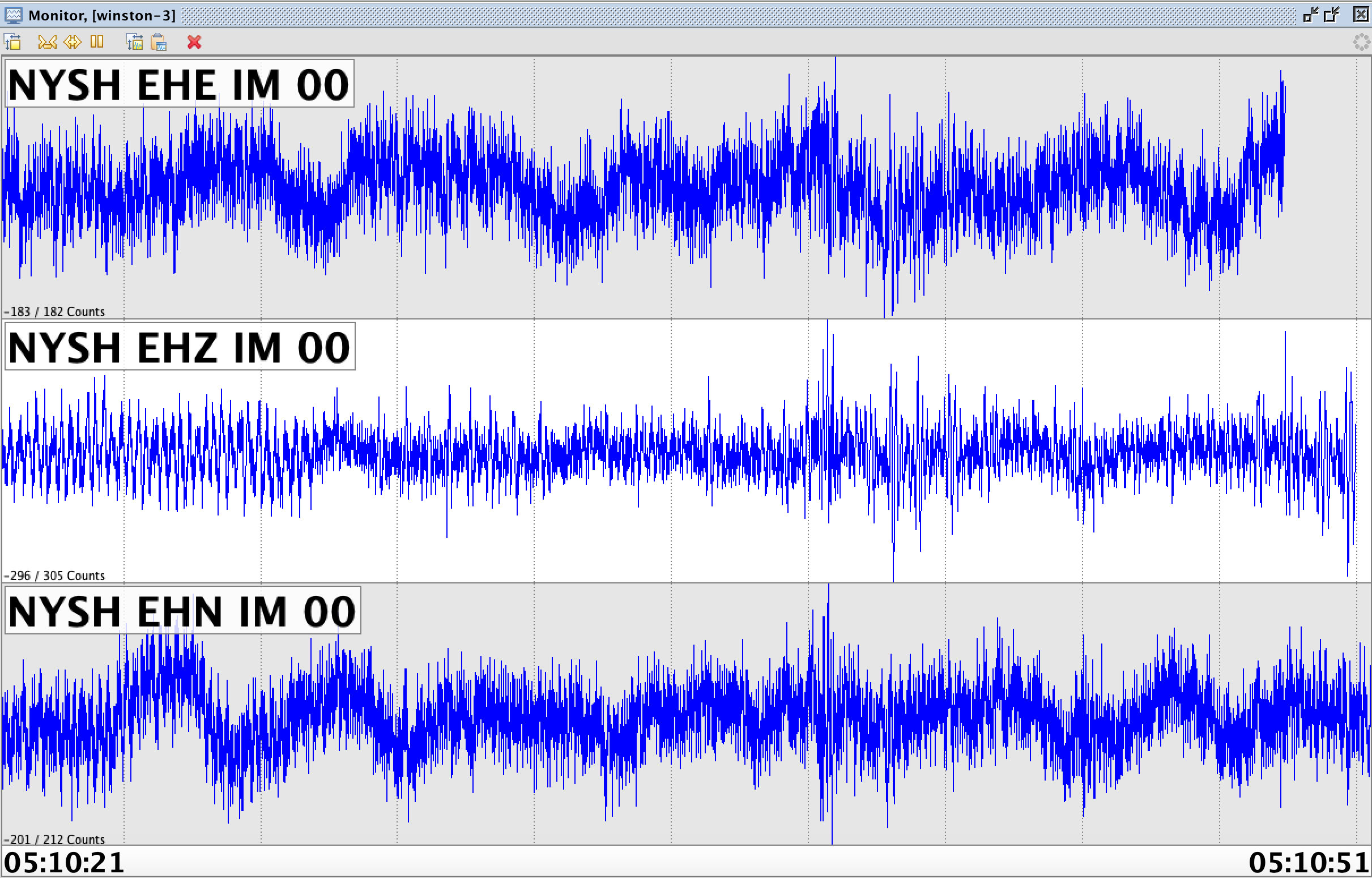
Типичные 30 секунд велосиметра на Севере Сахалина (землетрясений здесь нет)
Если мы посмотрим на запись прибора, то увидим, что в обычном режиме станция всегда что-то пишет. Представьте, что у вас очень чувствительный слух. Вы приложили ухо к земле и всё слышите: как течёт речка неподалёку, как бегут грунтовые воды, как шумят соседние населённые пункты. Если добавить к этому собственные колебания датчика, то мы получим картину, похожую на рисунок выше.
Локальная сеть сейсмических станций, в зависимости от площади мониторинга, как правило, насчитывает 10 и более приборов. Все станции пишут непрерывные суточные архивы. Эти данные не идеальны. В непрерывном потоке могут быть пропуски из-за продолжительных обрывов связи. Датчики и регистраторы иногда выходят из строя и пишут совсем не то, что нужно, и так далее.
Итак, представим, что данные у нас есть. Но прежде чем делать что-то новое (да ещё и c ML) давайте посмотрим какие проблемы возникают у сейсмологов на этапе выделения вступлений сейсмических волн.
«Старый» STA/LTA
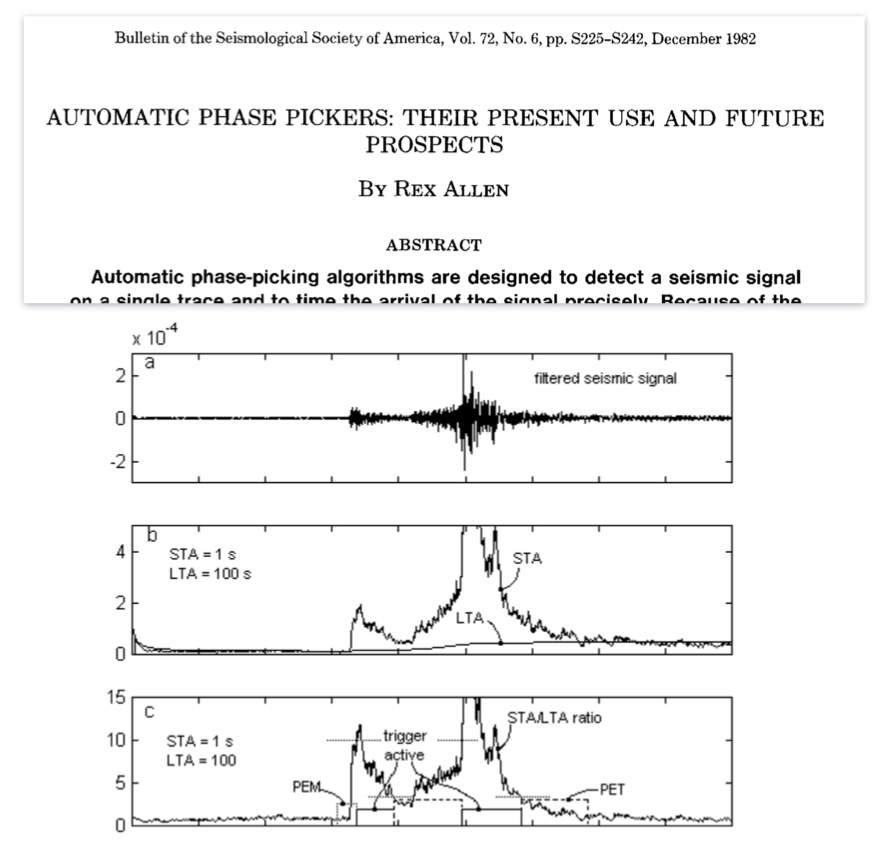
Заголовок исходной публикации 1982 года и суть метода
ftp://hazards.cr.usgs.gov/Eq_Effects/GeekPack/Procedures-Configs-Info/1_Dataloggers/K2-Altus/Sta-Lta. PDF
Несмотря на то, что этот алгоритм появился в 80-х годах он до сих пор активно используется в сейсмологических центрах в различных вариантах. Его суть очень проста — отмечать время там, где энергия сигнала за короткий промежуток времени превышает фоновые значения которые рассчитывается на более длинном интервале. Этот алгоритм прост как автомат Калашникова, но у него есть существенные недостатки:
Машинное обучение в сейсмологии
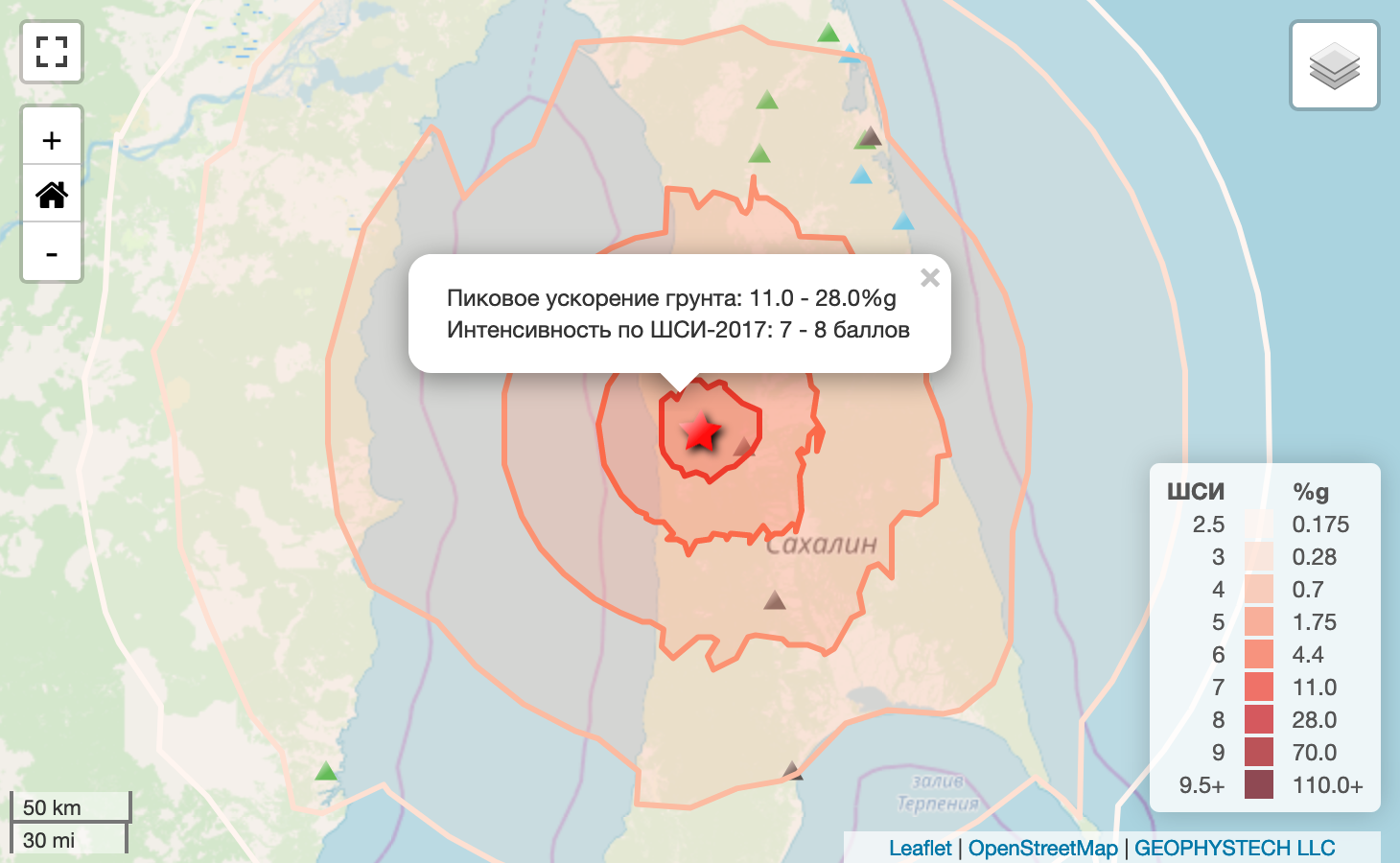
Землетрясение M6.1 на Севере Сахалина
https://eqalert.ru/#/events/QgpAn7OW
Все хотя бы раз слышали про землетрясения. Это опасное природное явление которое может привести к разрушению зданий, возникновению цунами и гибели людей. С помощью составления каталогов землетрясений и анализа сейсмической активности человечество пытается минимизировать риски от наступления сейсмических событий. Основной источник данных в сейсмологии — это непрерывные записи движения грунта, которые регистрируют с помощью сейсмических станций. Для того что бы составить представительный каталог землетрясений необходимо определить времена вступлений сейсмических волн в непрерывном потоке, рассчитать параметры очага и выполнить оценку магнитуды. Каждый этап рутинной обработки сейсмологических данных это предмет отдельной статьи, но мы с вами посмотрим на самое интересное — распознавание сейсмических волн методами машинного обучения. Определение времён вступлений сейсмических волн до сих пор выполняется (или корректируется) операторами-сейсмологами. Автоматизация этой сложной задачи позволит полностью исключить ручной труд при непрерывной обработке данных любой сейсмической сети. При этом, необходима такая модель, которая с одной стороны могла обеспечить точность отметок вступлений на уровне человека, а с другой была эффективна на этапе вывода (эксплуатация на CPU). Возможно ли это? Давайте посмотрим!
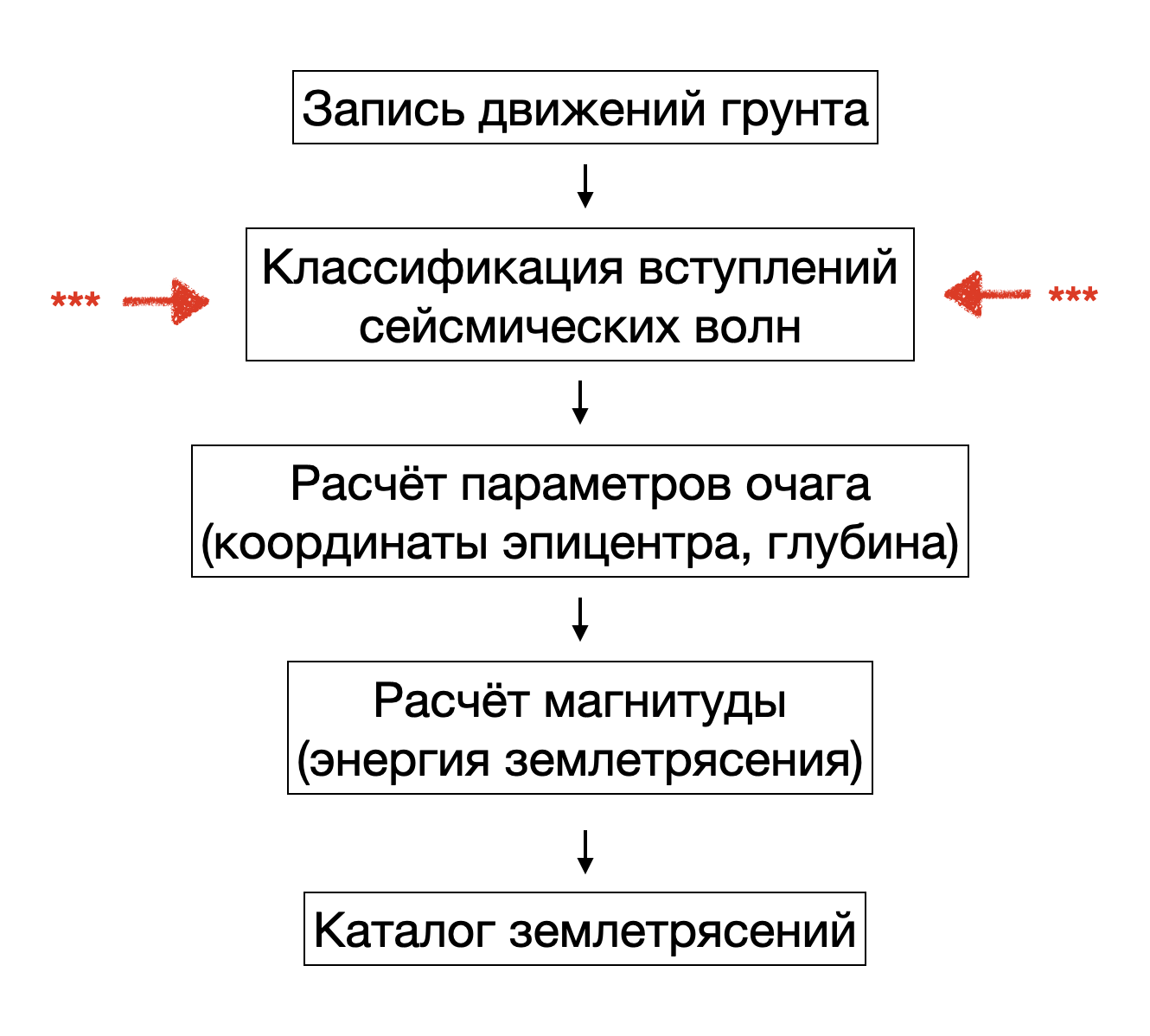
Основные этапы рутинной обработки сейсмологических данных
Простой классификатор коротких записей
Самое простое и интуитивное — это нарезать волновой ряд на короткие отрезки по 4-6 секунд. Каждый отдельный отрезок рассматриваем как образец (sample) который принадлежат к одному из классов: P-волна, S-волна или шум (Noise). Так как сейсмические волны имеют определённую характерную форму, по которой их узнаёт человек, то мы можем классифицировать наши данные как картинки, использую всю мощь соответствующих архитектур (например CNN). На этапе вывода волновой поток от сейсмостанции «нарезается» перекрывающимися окнами (что бы сигнал полностью попал в какое-то окно) и там, где вероятность выше заданного порога ставится отметка вступления. Наиболее удачная модель в этой области — это GPD.
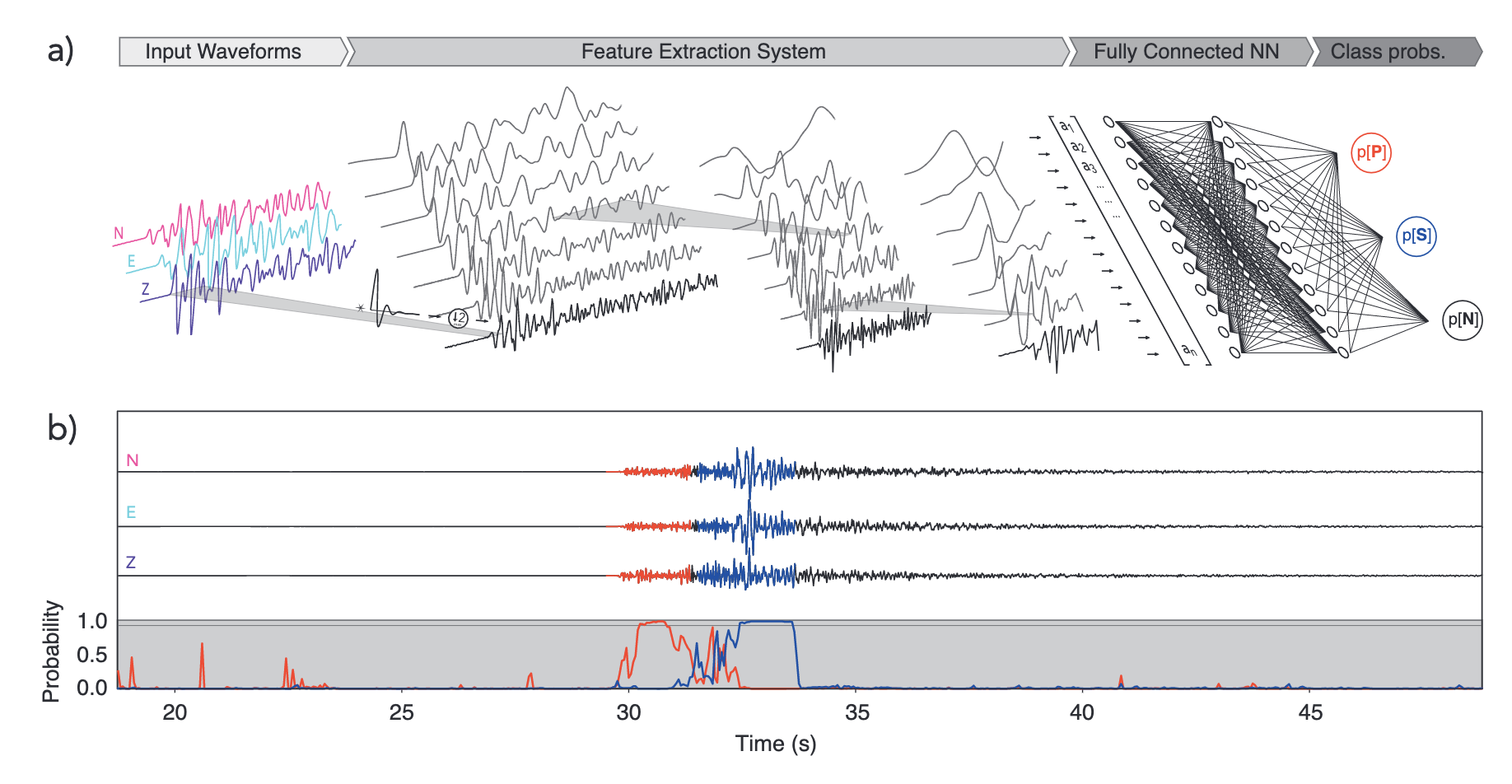
Ross, Z. E., Meier, M.-A., Hauksson, E., Heaton, T. H. (2018). Generalized Seismic Phase Detection with Deep Learning. ArXiv, 108(5A), 2894–2901. https://doi.org/10.1785/0120180080
Математическая модель укажет МЧС, где землетрясение будет ощущаться сильнее всего
Учёные впервые разработали модель затухания толчков, позволяющую точнее разрабатывать карты сейсмической опасности. Их используют в строительстве, чтобы оценить, какую силу землетрясений должны выдерживать здания в конкретном регионе. Также модель может использоваться для генерации карт сотрясаемости, по которым МЧС сможет понять, где последствия землетрясения, вероятно, будут сильнее всего. Результаты исследования, поддержанного грантом Российского научного фонда (РНФ), опубликованы в журнале Geosciences.
Для строительства любого здания нужно учитывать сейсмическую активность в регионе. В Чите (Забайкалье), где часто бывают землетрясения, можно строить панельные дома не выше пяти этажей, а в Москве, находящейся далеко от стыка литосферных плит, панельные дома часто строят девятиэтажными. При землетрясении от главного толчка распространяются горизонтальные колебания поверхности, которые затухают по определённому закону. Чтобы понять, какой толчок выдержит здание, нужно высчитать ускорение грунта.
Учёные из Дальневосточного геологического института ДВО РАН (Владивосток) разработали математическую модель, которая позволит рассчитать предполагаемое инерционное ускорение грунта. При её создании авторы использовали базу данных всех землетрясений, произошедших на Сахалине с 2006 года по 2022 год. При этом в рассмотрение включили как объективные показатели, например магнитуду (энергию в очаге землетрясения), так и субъективные — авторы опросили 600 местных жителей, чувствовали ли они толчки в определённый день. Такой опрос позволил собрать данные в тех местах, в которых нет приборов, высчитывающих ускорение. Кроме того, модель учитывала тип земной коры и грунта в местах проведения исследования.
Модель затухания толчков использует два основных показателя — геометрическое расхождение и характеристику сброшенного напряжения. Первый определяет, как распространяются сейсмические волны в пространстве. Также учитывается тип грунта: насколько сильно в нем затухают или усиливаются сейсмические ускорения, настолько слабее или сильнее могут быть воздействия на здание. Грунты делятся на три категории в зависимости от их состава и плотности. На Сахалине в месте проведения исследования грунты относятся к средней (второй) категории. В горах, на скалистых грунтах (первая категория) толчок ощущается чуть слабее, а в пустынях, на песках (третья категория) — сильнее.
Второй показатель — сброшенное напряжение — зависит от того, активная или стабильная земная кора в этом месте, насколько сильное напряжение скопилось при движении плит. Там, где нет активного движения плит, земная кора стойкая, и показатель сброшенного напряжения выше, так как плиты двигались медленно, и напряжение между ними скапливалось сотни и тысячи лет. Так как модель учитывает все виды грунта и все типы сейсмической активности, она может применяться для любого региона.
На основании вышеописанных показателей модель вычисляет ускорение грунта и определяет, насколько сильно будут ощущаться толчки в той или иной местности и землетрясения какой силы приведут к разрушению зданий. В результате можно создавать карты сейсмической опасности территорий, которые применяются при строительстве зданий. Кроме того, с помощью модели можно построить карту сотрясаемости. Ориентируясь на неё, МЧС понимает, в каком районе землетрясение, вероятно, вызвало максимальное воздействие и где колебания были сильнее всего.
«Мы надеемся, что наша модель станет основной для нормирования сейсмических воздействий в строительной отрасли России. В дальнейшем мы будем развивать базу данных и дорабатывать математические модели, чтобы их оценки были более точными и не подверженными разбросу. В наших ближайших планах — создание новой магнитудной шкалы для оперативного определения энергии землетрясения, поскольку существующие шкалы требуют длительного накопления данных и часто недооценивают силу крупных землетрясений», — рассказывает руководитель проекта, поддержанного грантом РНФ, Алексей Коновалов, кандидат физико-математических наук, ведущий научный сотрудник лаборатории лавинных и селевых процессов Дальневосточного геологического института РАН.
Тестирование производительности моделей
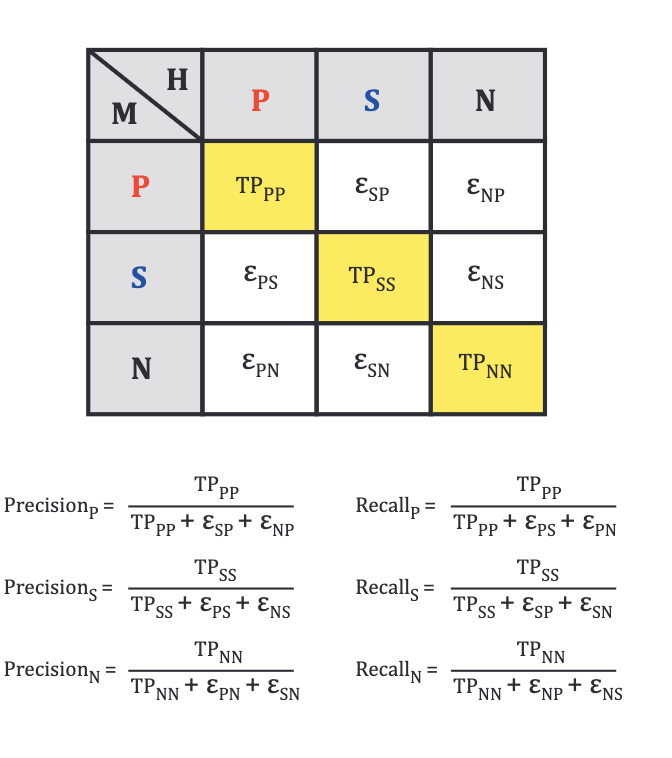
Теперь обучим наши модели. Для этого стандартно поделим обучающий датасэт на тренировочный и валидационный (80/20). Поставим раннюю остановку там, где сходимость по валидационным данным (validation loss) не улучшается в течении 5 эпох. Учить будем несколько раз что бы исключить случайно хороший результат. Поэтому после каждой итерации фиксируем результат для тестовых данных и всё заново.
Так как у нас три класса, то проверяем точность соответствующим образом. На этот счёт есть классная картинка от наших коллег из Калтэка.
Что бы протестировать производительность на этапе эксплуатации запустим наши модели на непрерывных данных. Поделим суточный архив одной сейсмической станции на перекрывающиеся окошки со сдвигом в 40 миллисекунд, получим 214К сэмплов, прогоним их на CPU и замерим время вывода. Для того что бы исключить накладные расходы на обращение к файловой системе (и много к чему ещё) измерять будем только время вывода самих моделей. А результаты сравним с топовой моделью GPD.
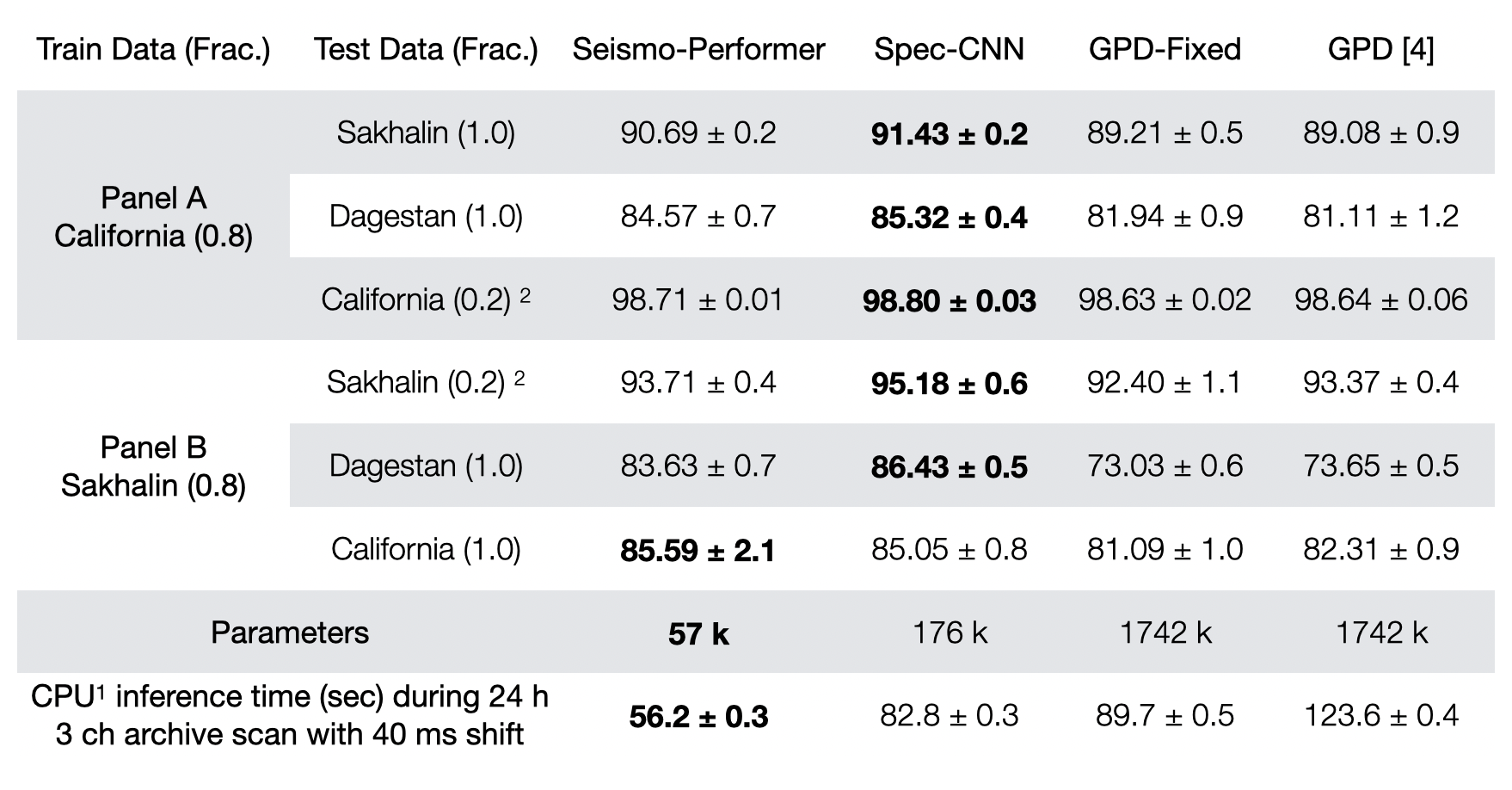
Тестирование моделей
Stepnov, A.; Chernykh, V.; Konovalov, A. The Seismo-Performer: A Novel Machine Learning Approach for General and Efficient Seismic Phase Recognition from Local Earthquakes in Real Time. Sensors 2021, 21, 6290. https://doi.org/10.3390/s21186290
В таблице представлена общая точность для тестируемых моделей. Seismo-Performer и Spec-CNN это наши новые модели. G DP — это оригинальная модель, а GPD-fixed это переобученная и GPD на tf 2.5.0. При обучении на Калифорнийских данных (Panel A) мы видим лучший результат по точности как для тестовых так и для валидационных данных у архитектур на базе спектрограмм. Интересно, что если обучить все модели на специфичном Сахалинском наборе (Panel B), который содержит на несколько порядков меньше примеров, то наши новые модели существенно лучше распознают данные, которые они раньше не видели. В целом, можно сделать вывод, что и Seismo-Performer и Spec-CNN обладают лучшей обобщающей способностью, им нужно меньше данных для сходимости, так что наш скромный трюк со спектрами сработал.
По производительность на этапе вывода лидирует Seismo-Performer: в 2,5 раза быстрее оригинально GPD и примерно на 35% быстрее своего соседа Spec-CNN. Здесь у нас чистая архитектура трансформера с оптимизацией FAVОR+ и минимальное количество параметров — всего 57k. По точности в абсолютных цифрах показатели немного ниже Spec-CNN, но +35% к скорости это существенно, с учётом того, что при эксплуатации это будет не одна станция а, например, 20.
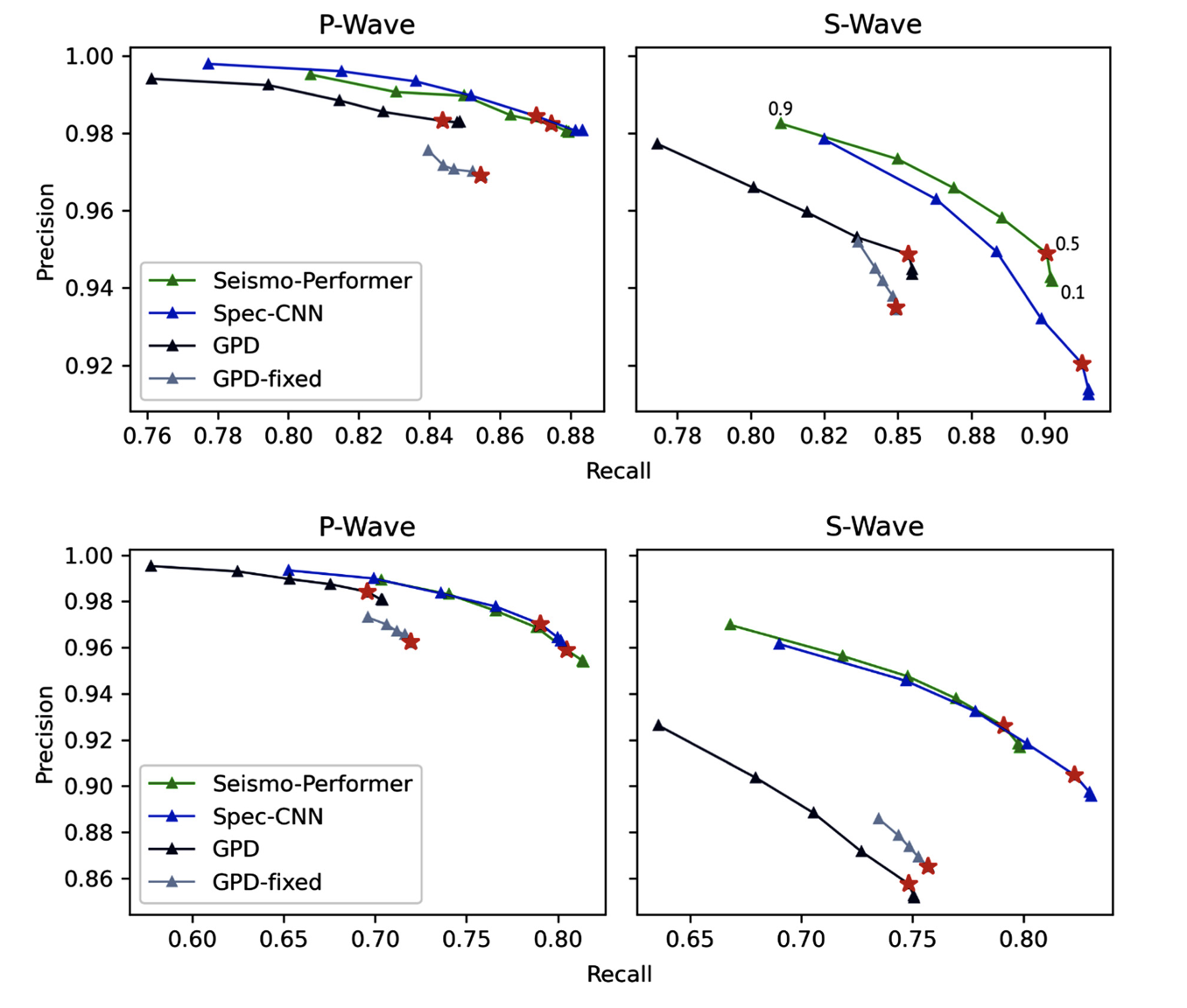
Если мы более подробно посмотрим на метрики производительности классификации, то увидим, что наши модели на основе спектров существенно лучше по показателю recall, а это значит, что они меньше «пропускают» полезный сигнал. Это очень важно на этапе эксплуатации, потому что ложные срабатывания всё же есть. Ложные срабатывания на реальных непрерывынх данных — это проблема всех существующих моделей. Дело в том при подготовке набора к обучению невозможно найти абсолютно все граничные случаи, когда сигнал является шумом, но он похож на реальное вступление. В качестве временного решения мы можем повысить порог значения SoftMax для класса при котором он будет считаться точным срабатыванием. Если у вас хороший recall, то вы можете сделать порог повыше и получить меньше пропусков и почти полное отсутсвие ложных срабатываний.
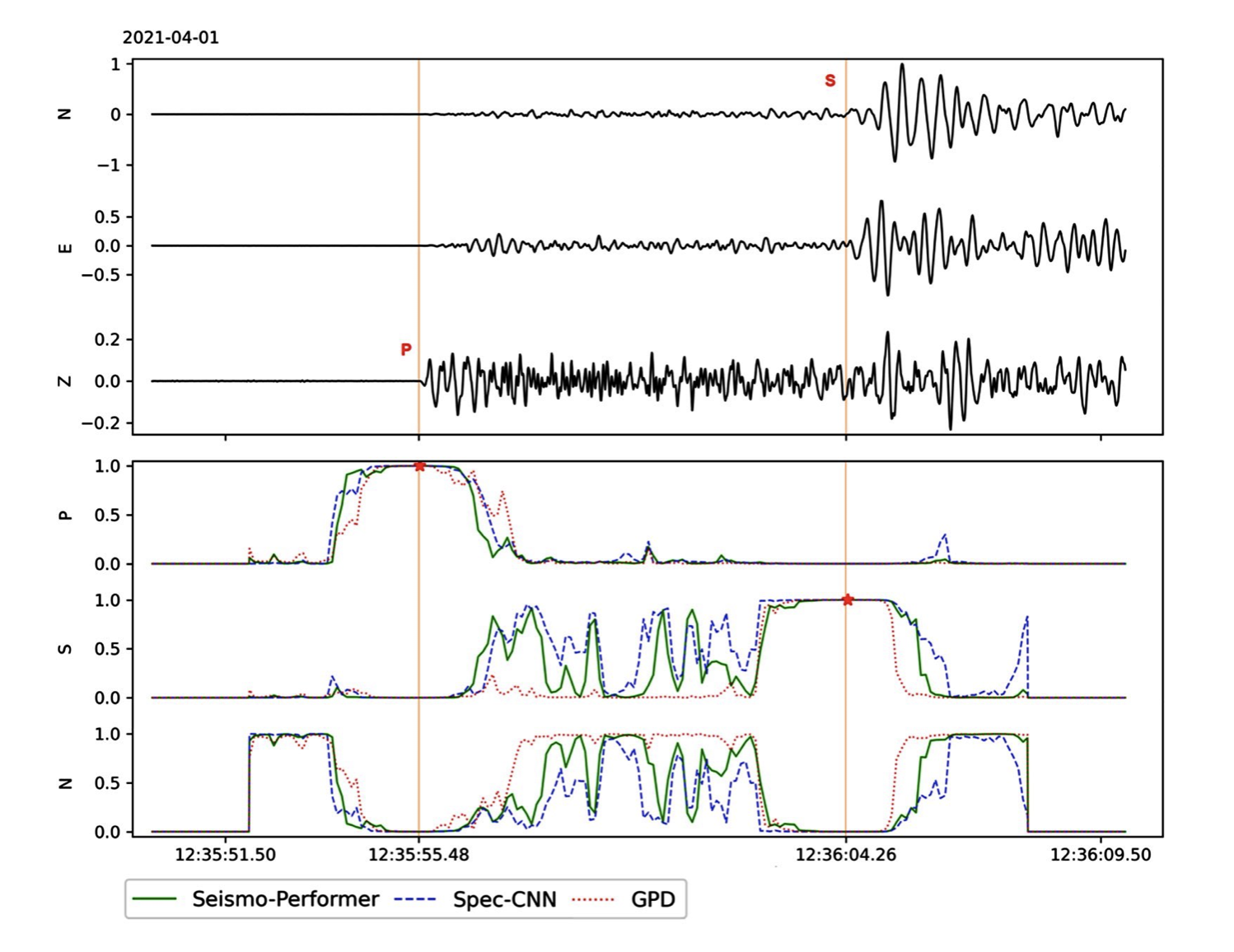
Это, можно сказать, конечный результат. Красные линии это отметки оператора. Звёздочки, это то что нашли модели (практически в одном месте для всех примеров). В качестве времени вступление выбирается «окошко» в котором вероятность на класс максимальна относительно соседних окон и выше заданного порога. Точность отметки в районе погрешности отметки оператора.
Deep learning
Итак, мы с вами добрались до самого интересного — это методы машинного обучения. Кроме очевидных преимуществ этого подхода, таких как распознавание именно формы сигнала и скорость вывода, стоит отметить открытые вопросы:
Давайте заглянем в научные работы и посмотрим как там обстоят дела. Если исключить совсем пионерские работы, то основная масса научных статей на эту тему опубликована в последние пять лет. Нужно дополнительно очертить наше поле исследований: мы будем говорить о локальных землетрясениях, то есть о таких событиях, когда расстояние от очага до сейсмической станции не превышает 300 километров. Выделять мы будем P и S волны от локальных землетрясений. Сейчас можно уверенно говорить о существовании двух подходов к этой задаче.
Кросс-корреляция и сопоставление шаблонов
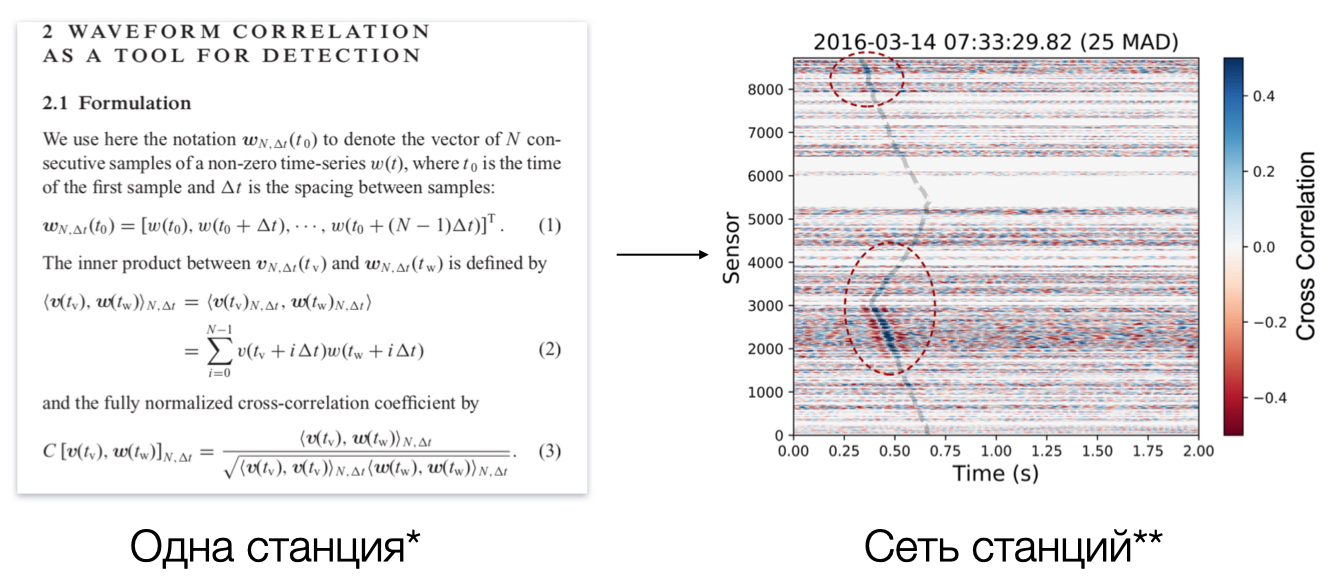
Этот метод начал активно применяться с начала 2000-х когда вычислительные мощности позволили выполнить это. Алгоритм способен находить очень слабые землетрясения. Кросс-корреляция активно используется для восстановления афтершоковых последовательностей. Дело в том, что когда происходит сильное землетрясение то следом за главным событием обычно происходят тысячи более слабых землетрясений. Если в качестве мастер-события задать главный толчок, то тогда поиск других землетрясений из этой же очаговой зоны будет успешен. Однако, у этого метода есть главный недостаток: нет мастер-события — нет результата. Если землетрясение произойдет в другой очаговой зоне, то мы ничего не увидим. То есть применять этот алгоритм для решения наших проблем затруднительно, так как мы не знаем заранее где возникнет сейсмическое событие.
Заключение
Мы с вами посмотрели специфичную задачу из области наук о Земле. На выходе мы получили ML-модели которые отмечают вступления сейсмических волн на уровне оператора-сейсмолога. За счёт применения спектрограмм у нас получилось сделать сигнал более четким и улучшить обобщающую способность. А современные наработки из NLP позволили сделать очень быструю модель, которая может работать на CPU и готова к внедрению в сейсмологических дата центрах.
Оригинальная работа, репозиторий на GitHub c данными и плейбуками.
Спасибо, что дочитали до конца.